python
Table of Contents
- 1. python
- 1.1. Awesome python
- 1.2. Resources
- 1.3. Clean Code Python
- 1.4. Youtube Python youtube
- 1.5. Cosas rarunas de python
- 1.6. Tricks
- 1.7. Writing faster python
- 1.8. Diferencias entre Multiprocessing en Windows y Linux
- 1.9. Venvs de python ARCHIVE
- 1.10. HyLang (Python functional como lisp)
- 1.11. Noticias nuevas
- 1.11.1. Multi interptreter / Remove GIL
- 1.11.1.1. A viable solution for Python concurrency [LWN.net]
- 1.11.1.2. Removing the GIL: Notes From the Meeting Between Core Devs and the Author of the `nogil` Fork
- 1.11.1.3. PEP 684 – A Per-Interpreter GIL
- 1.11.1.4. The Python GIL: Past, Present, and Future
- 1.11.1.5. PEP 684: A Per-Interpreter GIL - PEPs - Discussions on Python.org
- 1.11.1.6. PEP 703: Making the Global Interpreter Lock Optional - PEPs : programming
- 1.11.1.7. PEP 703 – Making the Global Interpreter Lock Optional in CPython : Python
- 1.11.1.8. GIL PyConES
- 1.11.2. Static Typing
- 1.11.2.1. https://github.com/typeddjango/awesome-python-typing
- 1.11.2.2. https://github.com/ethanhs/python-typecheckers
- 1.11.2.3. mypyc/mypyc Mypyc compiles Python modules to C extensions
- 1.11.2.4. Tipos en numpy
- 1.11.2.5. Tipos de tipado
- 1.11.2.6. python sucks (typing and static)
- 1.11.2.7. Static type checking
- 1.11.2.8. The Comprehensive Guide to mypy
- 1.11.2.9. PEP 673 – Self Type
- 1.11.3. Pandas column typing
- 1.11.4. PEP622 Structural Pattern Matching
- 1.11.4.1. markshannon/pep622-critique: Put all the objections to PEP 622 in one place.
- 1.11.4.2. PEP 622 (Structural Pattern Matching) superseded by PEPs 634, 635 and 636
- 1.11.4.3. PEP 642 – Constraint Pattern Syntax for Structural Pattern Matching
- 1.11.4.4. A look the new pattern matching in Python 3.10.0a6
- 1.11.4.5. Pattern matching tutorial for Pythonic code
- 1.11.5. “New Features in Python 3.10”
- 1.11.6. PEP 657 : Fine grained locations in tracebacks merged to Python 3.11
- 1.11.7. TICKLER Python in the Browser track
- 1.11.7.1. Pyodide: Python + Data Stack in the browser
- 1.11.7.2. Pyodide: A Project Aimed At Providing The Complete Python Data Science Stack Running Entirely In The Browser
- 1.11.7.3. Using Python for Frontend (Pyodide Alternatives)
- 1.11.7.4. Welcome to the world PyScript
- 1.11.7.5. Portable python
- 1.11.7.6. Python wasm
- 1.11.7.7. flexxui/flexx: Write desktop and web apps in pure Python
- 1.11.8. Production-ready Docker packaging for Python developers
- 1.11.9. New Python Releases
- 1.11.10. When to switch to <insert new Python release>
- 1.11.11. PEP 671: Syntax for late-bound function defaults
- 1.11.12. DONE API para arrays y dataframes
- 1.11.1. Multi interptreter / Remove GIL
- 1.12. Python Refactoring
- 1.13. line_profiler and memory_profiler
- 1.14. Python Software Foundation News: Amber Brown: Batteries Included, But They’re Leaking
- 1.15. Estructura de proyectos
- 1.16. Cyberbrain: Python debugging, redefined
- 1.17. WSGI w/ Greenlets/Gevent vs. ASGI
- 1.18. Python Internals
- 1.19. pandas
- 1.20. Dataclasses
- 1.21. testing
- 1.22. pdb, Python REPL
- 1.23. async Python
- 1.24. Python Distributed MapReduce with Parallel Processing
- 1.24.1. Executing a distributed shuffle without a MapReduce system | Distributed Computing with Ray
- 1.24.2. What is Ray? — Ray v2.0.0.dev0
- 1.24.3. RayOnSpark: Running Emerging AI Applications on Big Data Clusters with Ray and Analytics Zoo | by Jason Dai | riselab | Medium
- 1.24.4. modin-project/modin: Modin: Speed up your Pandas workflows by changing a single line of code
- 1.24.5. How to process a DataFrame with millions of rows in seconds
- 1.25. Python Alternative interpreters
- 1.25.1. Cinder: Instagram’s internal performance-oriented production version of CPython 3.8
- 1.25.2. Pyston v2.2: faster and open source (30% faster than stock Python)
- 1.25.3. OpenAI releases Triton: Python-like language for GPU programming
- 1.25.4. PyPy: Faster Python With Minimal Effort – Real Python
- 1.25.5. pfalcon/pycopy: Pycopy - a minimalist and memory-efficient Python dialect. Good for desktop, cloud, constrained systems, microcontrollers, and just everything.
- 1.25.6. MicroPython - Python for microcontrollers
- 1.26. Hash of python function
- 1.27. Visualization
- 1.28. numpy
- 1.29. Alternatives to CSV
- 1.30. FastAPI, Uvicorn, Gunicorn…
- 1.31. Optimización
- 1.32. sympy
- 1.33. Concurrencia
- 1.34. Python logging
- 1.35. Dokuwiki
- 1.35.1. pip freeze
- 1.35.2. links
- 1.35.3. trucos
- 1.35.3.1. Python.h: No such file or directory
- 1.35.3.2. Conversión rápida de casi-json espaciado con pprint a json
- 1.35.3.3. Recorrer un directorio recursivamente
- 1.35.3.4. Recargas dinámicas con pdb
- 1.35.3.5. Conversiones de fecha con pytz
- 1.35.3.6. async debugging
- 1.35.3.7. python debugger (pdb) con múltiples líneas
- 1.35.3.8. Trabajando con warnings
- 1.35.3.9. debugging
- 1.35.3.10. Sacar la traza cuando no hay excepción
- 1.35.4. memoryview
- 1.35.5. listas
- 1.35.6. collections
- 1.35.7. slices
- 1.35.8. print, f-strings, formato
- 1.35.9. map, filter, reduce
- 1.35.10. lambda
- 1.35.11. Diccionarios
- 1.35.12. funciones
- 1.35.13. Clases
- 1.35.14. sequences
- 1.35.15. resumen
1. python
1.1. Awesome python
- https://github.com/huangsam/ultimate-python
Ultimate Python study guide for newcomers and professionals alike - https://github.com/uhub/awesome-python
- https://github.com/vinta/awesome-python
- dylanhogg/crazy-awesome-python: A curated list of awesome Python frameworks, with a bias towards data and machine learning
- trananhkma/fucking-awesome-python; A curated list with Github stars and forks stats based on vinta/awesome-python
- TimeComplexity - Python Wiki
This page documents the time-complexity (aka “Big O” or “Big Oh”) of various operations in current CPython
1.2. Resources
- Begginner Resources
- Python official tutorial: https://docs.python.org/3/tutorial/
- READ https://jakevdp.github.io/WhirlwindTourOfPython/ Programming Focused
- READ https://jakevdp.github.io/PythonDataScienceHandbook/ Data Science Focused (IPython, NumPy, Pandas, Matplotlib, Scikit-Learn)
- 🏠️ Inicio | El Libro De Python
- Think Python, 3rd edition — Think Python, 3rd edition
- Python for Data Analysis, 3E
- Pandas Illustrated: The Definitive Visual Guide to Pandas
- https://github.com/hektorprofe/curso-python-udemy
- Slither into Python Aprender Python a la vez que te enseñan los fundamentos de más bajo nivel
- The Hitchhiker’s Guide to Python!
- Python official tutorial: https://docs.python.org/3/tutorial/
- Advanced Resources
- READ Fluent Python [Book] Advanced but also Comprehensive
- Python Distilled [Book] Minimalistic, from what I see from the ToC has an emphasis on Protocols and Module/Packaging
- Effective Python › The Book: Second Edition Has DRM-free version, distributed queues
- READ Fluent Python [Book] Advanced but also Comprehensive
- https://pythontutor.com/ Run Python, Java, C, C++, JavaScript, and Ruby code interactively
- PythonBooks - Python Wiki
1.2.1. Blogs
1.2.3. Python 3 Module of the Week — PyMOTW 3
1.3. Clean Code Python
1.3.1. Links
1.3.2. Separación de conceptos con iteradores
Con colas se da mucho el caso en el que vamos quitando elemento de la
cola hasta que se queda vacía, o hasta que eliminamos todos los
elementos urgentes.
Para evitar usar variables definidas en main como data y
current_element:
def main(): import Queue transactions = Queue.SimpleQueue() . . data = [] processed_transactions = [] current_element = q.get_nowait() for transaction in transactions: apply(q, account) processed_transactions.append(transaction.id) def apply(q, account): . . while account.status == OK: data.append(current_element) current_element = q.get_nowait() . .
Limpiamos el código creando un iterable
def main(): import Queue transactions = Queue.SimpleQueue() . . data = [] for transaction in apply(transactions, account): data.append(transaction) processed_transactions.append(transaction.id) def apply(q, account): # Procesamos el primero como caso especial current_element = q.get_nowait() yield process(current_element) while account.status == OK: yield process(current_element) current_element = q.get_nowait()
Así separamos logramos que la función apply no sepa nada de la lista
data y que la función main no sepa nada de current_element
1.3.3. single quotes vs double quotes
https://stackoverflow.com/questions/56011/single-quotes-vs-double-quotes-in-python
doble quotes
- Natural language messages
- Filenames
- docstrings or large strings -> triple double quotes
"""
single quotes
- Symbol-like strings
- dict keys (unless they are natural language)
- f-strings
- regexs
Break the rules if the strings contain quotes
"A literal 'quote' inside a string" 'A literal "quote" inside a string'
1.3.4. import recomendados
.
|-- common
| |-- __init__.py
| |-- models.py
| |-- views.py
| |-- controllers.py
| `-- plugins
| |-- __init__.py
| |-- display.py
| `-- parallel.py
`-- interactive
|-- __init__.py
|-- main.py
|-- actions
| `-- click.py
| `-- select.py
`-- events
|-- __init__.py
|-- onclick.py
`-- onselect.py
# common/models.py if __name__ == "__main__": main()
- Cuando hacemos un import, se ejecuta todo el script. Para evitar que
se ejecute el script cuando importamos, sólo lo ejecutamos si
__name__ =“main”= - Si hacemos
import commonse ejecuta./common/__init__.py, pero si
no existe, falla
1.3.4.1. Importar saltándose los init
from common.plugins import displaypuede que ejecute los
__init__.pydecommonyplugins. Para evitarlo;
import sys # Lo pongo en una línea porque no es separable conceptualmente sys.path.append('common/plugins'); import display
1.3.4.2. reloads
# Cuando importamos código de otras librerías, podemos hacer sin problema from module import function # Pero cuando estamos trabajando con módulos propios, conviene importarlos siempre # con el nombre del módulo import module foo = module.function() # Así cuando cambiamos module, podemos recargarlo sin tener que reiniciar IPython: from importlib import reload reload(module)
1.3.5. fluent interfaces multiline
html = ( df.style .format(percent) .applymap(color_negative_red, subset=['col1', 'col2']) .set_properties(**{'font-size': '9pt', 'font-family': 'Calibri'}) .bar(subset=['col4', 'col5'], color='lightblue') .render() )
1.3.6. Parametrizable Retry Decorator
def retry(trials=3): def decorate(func): def newfunc(*args, **kwargs): n = 1 while n <= trials: try: print(f"Trial number {n}") return func(*args, **kwargs) except TimeoutError as error: print(f"TimeoutError: {error}") n += 1 return newfunc return decorate @retry(trials=9) def myfunction(): pass
1.3.7. Simple Breakpoint Decorator
def decorate(func): def newfunc(*args, **kwargs): try: return func(*args, **kwargs) except: breakpoint() return newfunc
1.3.8. Ejecución con map
import concurrent.futures as futures workers = 4 with futures.ThreadPoolExecutor(workers) as executor: res = executor.map(function, iterable) with futures.ProcessPoolExecutor(workers) as executor: res = executor.map(function, iterable)
https://docs.python.org/3/library/concurrent.futures.html#executor-objects
1.3.9. Laziness in Python
from itertools import takewhile def f(n): for i in range(n): yield i print(i) list(filter(lambda x: x==4, f(5))) # Not lazy list(takewhile(lambda x: x<2, f(5))) # Lazy, but only can take from the front
1.3.9.1. Multiple functions
from itertools import takewhile def f(n): for i in range(n): yield i print(i) def g(): f1 = list(f(1)) f2 = list(f(2)) f3 = list(f(3)) yield f3 yield f2 yield f1 list(takewhile(lambda x: len(x)>2, g()))
1.4. Youtube Python youtube
1.5. Cosas rarunas de python
1.6. Tricks
Llamar a funciones en la carpeta padre
import sys sys.path.insert(0, "..")
Redirigir
prints
from contextlib import redirect_stdout with open('/dev/null', 'w') as f: with redirect_stdout(f):
1.7. Writing faster python
https://switowski.com/tag/writing-faster-python/ Benchmarkings en python
1.8. Diferencias entre Multiprocessing en Windows y Linux
Cuando creas un proceso nuevo en Linux hace un fork(), lo que significa que copia las variables que tenga en ese momento el programa
En Windows no pasa esto sino que spawnea , por lo que algo que funciona en Linux puede que no funcione en Windows
Además cuando se crea un nuevo proceso en Windows se importa el paquete por lo que tiene que estar todo en
https://stackoverflow.com/questions/6596617/python-multiprocess-diff-between-windows-and-linux
1.9. Venvs de python ARCHIVE
1.10. HyLang (Python functional como lisp)
1.11. Noticias nuevas
Cosas que estoy siguiendo de python
1.11.1. Multi interptreter / Remove GIL
1.11.1.1. A viable solution for Python concurrency [LWN.net]
1.11.1.2. Removing the GIL: Notes From the Meeting Between Core Devs and the Author of the `nogil` Fork
1.11.1.3. PEP 684 – A Per-Interpreter GIL
1.11.1.4. The Python GIL: Past, Present, and Future
1.11.1.8. GIL PyConES
Biased reference counting | Proceedings of the 27th International Conference on Parallel Architectures and Compilation Techniques
https://dl.acm.org/doi/10.1145/3243176.3243195
Objetos inmortales: el contador de referencia es muy grande y no se decrementa (objetos compartidos que se usan mucho en python)
Deferred reference counting: compensa incrementos y decrementos y no hace nada (1 - 1 = 0)
1.11.2. Static Typing
1.11.2.3. mypyc/mypyc Mypyc compiles Python modules to C extensions
1.11.2.4. Tipos en numpy
https://numpy.org/devdocs/release/1.20.0-notes.html#numpy-is-now-typed → desde 1.20.0 están incluidas, si no instalar utilizando:
pip install git+https://github.com/numpy/numpy-stubs
https://github.com/numpy/numpy/issues/16544 → tipado de shape, para estar de acuerdo en las dimensiones de algo
1.11.2.5. Tipos de tipado
1.11.2.6. python sucks (typing and static)
1.11.2.7. Static type checking
Comprobar si ya existe para pandas Pandas stub type checking
- !https://github.com/predictive-analytics-lab/data-science-types! → parece el mejor, es para numpy, matplotlib y pandas
The pandas team and the numpy team are both in the process of integrating type stubs into their codebases, and we don’t see the point of competing with them.
https://zsailer.github.io/software/pandas-flavor/
https://github.com/typeddjango/awesome-python-typing En python 3.8 ya existen:
https://www.python.org/dev/peps/pep-0589/ Pero parece que para pandas no valen
todavía https://github.com/pandas-dev/pandas2/issues/18
https://github.com/pandas-dev/pandas/issues/14468
https://github.com/pandas-dev/pandas/issues/26766 Alguien ha escrito algunas
cosas:
https://stackoverflow.com/questions/41105819/mypy-typeshed-stubs-for-pandas
1.11.2.8. The Comprehensive Guide to mypy
1.11.2.9. PEP 673 – Self Type
Anotar la propia clase que estas definiendo
https://www.reddit.com/r/Python/comments/qrs0vq/pep_673_self_type/
1.11.3. Pandas column typing
1.11.4. PEP622 Structural Pattern Matching
1.11.4.1. markshannon/pep622-critique: Put all the objections to PEP 622 in one place.
1.11.4.2. PEP 622 (Structural Pattern Matching) superseded by PEPs 634, 635 and 636
1.11.4.3. PEP 642 – Constraint Pattern Syntax for Structural Pattern Matching
1.11.4.4. A look the new pattern matching in Python 3.10.0a6
1.11.4.5. Pattern matching tutorial for Pythonic code
1.11.5. “New Features in Python 3.10”
“New Features in Python 3.10” por James Briggs
https://link.medium.com/t4PooWpvvbb
1.11.6. PEP 657 : Fine grained locations in tracebacks merged to Python 3.11
1.11.7. TICKLER Python in the Browser track
1.11.7.1. Pyodide: Python + Data Stack in the browser
- https://devblogs.microsoft.com/python/feasibility-use-cases-and-limitations-of-pyodide/
Trae estos paquetes instalados y puede instalar cualquiera de python puro: https://github.com/pyodide/pyodide/tree/main/packages
Tiene soporte de Node.js: https://github.com/pyodide/pyodide/issues/14 (Inicialmente muy reducido https://github.com/pyodide/pyodide/pull/1691)
Aplicaciones multiarchivo es complicado: https://github.com/pyodide/pyodide/issues/419, recomiendan hacer un paquete y alojarlo en un repo estilo PyPI (imagino que repo de git también vale)
https://github.com/pyodide/pyodide/issues/1715
1.11.7.2. Pyodide: A Project Aimed At Providing The Complete Python Data Science Stack Running Entirely In The Browser
1.11.7.3. Using Python for Frontend (Pyodide Alternatives)
1.11.7.4. Welcome to the world PyScript
https://engineering.anaconda.com/2022/04/welcome-pyscript.html
Build on top of:
- WebAssembly/WASM: a portable binary-code format and text format for executable programs & software interfaces to enable high performance applications on web pages and other environments
- Emscripten(https://emscripten.org/): an Open Source compiler toolchain to WebAssmbly, practically allowing any portable C/C++ codebase to be compiled into WebAssembly
- Pyodide(https://pyodide.org/)/python-wasm(https://github.com/ethanhs/python-wasm): Python implementations compiled to WebAssembly
- https://hacs-pyscript.readthedocs.io/en/stable/overview.html
- https://twitter.com/pwang/status/1521137668003880961
- Heavyweight (10MB core, 100MB pandas)
1.11.7.5. Portable python
1.11.7.6. Python wasm
1.11.8. Production-ready Docker packaging for Python developers
1.11.8.1. Imágenes de Alpine para python
https://www.python.org/dev/peps/pep-0656/
Esto significa que vas a poder usar un Alpine como imagen de docker sin tener que compilar pandas
https://pythonspeed.com/articles/alpine-docker-python/
Utilizan musl en vez de glibc como librería de c, entonces wheels las están compiladas con glibc
1.11.9. New Python Releases
1.11.9.1. Python Release Python 3.11.0 | Python.org
- PEP 655 – Marking individual TypedDict items as required or potentially-missing | peps.python.org
- Python 3.11.0 is released — Impacts to Data Science and Engineering | by Christianlauer | CodeX | Oct, 2022 | Medium
- PEP 673 – Self Type | peps.python.org
- PEP 675 – Arbitrary Literal String Type | peps.python.org
- PEP 681 – Data Class Transforms | peps.python.org
- PEP 646 – Variadic Generics | peps.python.org
1.11.10. When to switch to <insert new Python release>
https://pythonspeed.com/articles/major-python-release/
- Missing Docker images
- Missing binary packages
- Incompatible packages
- Lack of Conda support
- Bugs in Python
- Lack of toolchain support
At a minimum, you will need to wait until:
- All your libraries explicitly support the new Python release.
- All the tools you rely on explicitly support the new Python release.
1.11.10.1. Why you can’t switch to Python 3.10 just yet
1.11.10.2. When should you upgrade to Python 3.11?
1.11.11. PEP 671: Syntax for late-bound function defaults
1.11.12. DONE API para arrays y dataframes
Se abandonó
- https://data-apis.org/blog/announcing_the_consortium/
- https://data-apis.org/
- Python array API standard — Python array API standard latest documentation
- Python dataframe interchange protocol — Python dataframe interchange protocol latest documentation
- https://github.com/data-apis/dataframe-interchange-tests → Dask no está incluido, pero el estándar todavía no está publicado
- https://github.com/data-apis/dataframe-interchange-tests → Dask no está incluido, pero el estándar todavía no está publicado
- Python array API standard — Python array API standard latest documentation
- https://labs.quansight.org/blog/2021/10/dataframe-interchange-protocol-and-vaex/
- https://labs.quansight.org/blog/2021/10/array-libraries-interoperability/
1.11.12.1. Ver este episodio de estandarización de interfaces de Python
https://connectedsocialmedia.com/19691/building-common-standards-for-python-data-apis/
https://media21.connectedsocialmedia.com/intel/11/19691/Building_Common_Standards_Python_Data_APIs.pdf
Es más un tema social de utilizar la misma o librería y no crear 40 distintas que un tema técnico
1.12. Python Refactoring
- ast no te preserva los comentarios
- rope tiene mala documentación para cuando lo quieres usar de manera programática
- treesitter es muy sencillo
Aprender Treesitter
1.14. Python Software Foundation News: Amber Brown: Batteries Included, But They’re Leaking
Poor Quality, Lagging Features, And Obsolete Code Some ecosystems such as
Javascript rely too much on packages, she conceded, but there are others like
Rust that have small standard libraries and high-quality package repositories.
She thinks that Python should move farther in that direction.
http://pyfound.blogspot.com/2019/05/amber-brown-batteries-included-but.html?m=1
1.15. Estructura de proyectos
- La que estoy usando ahora es llamar siempre desde root, pero PyCharm por ejemplo siempre llama desde la carpeta en la que se ejecuta el script
- Hacen esto para tener una carpeta principal en la que tienes las funciones que llaman al resto del código
- Para llamar a una función o bien tienes que utilizar un script que esté en la carpeta principal (
python script.py) o bien puedes llamar a submódulos (python -m src.main, donde hay unimport utils.packagede carpeta hermana) - ↑ Te obliga a tener una estructura más limpia si estás desarrollando aplicaciones o paquetes no muy abiertos
- ↓ Menos flexible para desarrollar. No puedes escribir scripts en carpetas que llamen a código en otras carpetas hermanas, tiene que estar todo en la carpeta principal. Si hay mucha gente trabajando se convierte en un jaleo, muchos scripts
- Hacen esto para tener una carpeta principal en la que tienes las funciones que llaman al resto del código
- Una de las alternativas es poner un
__init__.py - La otra alternativa es meter un setup.py en tu proyecto y ya puedes llamar a todo desde todas partes
1.15.1. Queries en .sql vs queries en .py
1.15.1.1. Queries en .sql
- ↑ No están cacheadas en python
- ↓ No puedes juntar muchas queries pequeñas en un archivo (o tienes que hacer split y entonces cada query no tiene un nombre único)
1.15.1.2. Queries en .py
- ↓ Las queries están cacheadas
- ↑ Cada query tiene un nombre único
1.16. Cyberbrain: Python debugging, redefined
1.17. WSGI w/ Greenlets/Gevent vs. ASGI
1.18. Python Internals
1.18.1. Python behind the scenes #1: how the CPython VM works
1.18.2. PEG Parsing Series Overview. My series of blog posts about PEG… | by Guido van Rossum | Medium
1.18.3. How Python list really works
https://antonz.org/list-internals/
List = array of pointers
Array extension is a costly operation – O(n) –, so the new array should be significantly larger than the old one. Python uses a modest coefficient – about 1.12 – to extend the array
If you remove more than half of the items from the list via .pop(), Python will shrink it. It’ll allocate a new, smaller array and move the elements into it.
Selecting from the list by index takes O(1) time
the amortized time for .append(item) turns out to be constant – O(1)
- As we found out, these operations are O(1):
- select an item by index lst[idx]
- count items len(lst)
- add an item to the end of the list .append(item)
- remove an item from the end of the list .pop()
- select an item by index lst[idx]
- Other operations are “slow”:
- Insert or delete an item by index. .insert(idx, item) and .pop(idx) take linear time O(n) because they shift all the elements after the target one.
- Search or delete an item by value. item in lst, .index(item) and .remove(item) take linear time O(n) because they iterate over all the elements.
- Select a slice of k elements. lst[from:to] takes O(k).
- Insert or delete an item by index. .insert(idx, item) and .pop(idx) take linear time O(n) because they shift all the elements after the target one.
1.19. pandas
1.20. Dataclasses
Se pueden utilizar DataClasses, que nos dan:
- Inmutabilidad de las clases de datos (si vamos a transformar, hay que declararlo explícitamente)
- Errores de tipos con mypy (linting)
- Tiene pattern matching de datos, permite hacer “queries” a los datos
- Paserle un argumento
slots=Truepara que sea más rápido (lo único que pierdes es herencia múltiple)
Una opción alternativa es Pydantic que tiene validación de datos, también tiene un dataclass
1.20.0.1. How did I change my mind about dataclasses in ML projects?
Dataclasses dentro de dataclasses, pydantic y demás
1.20.0.2. https://jsontopydantic.com/
1.21. testing
1.21.1. “Automating Unit Tests in Python with Hypothesis” tests
“Automating Unit Tests in Python with Hypothesis” by Niels Goet
https://link.medium.com/2mb1HDfTo9
1.21.2. unittest vs pytest
- Python Unittest Vs Pytest: Choose the Best - Python Pool
- unittest: standard library, sequential, more verbose
- pytest: parallel, unless you use a plugin, scales as you need (small tests don’t pay the price of big tests)
- unittest: standard library, sequential, more verbose
1.21.3. pytest
- Manage tests with coroutines like Climbing Mount Effect
- Anatomy of a test — pytest documentation
- How to use fixtures — pytest documentation
- https://github.com/pluralsight/intro-to-pytest
- “Advanced pytest techniques I learned while contributing to pandas” por Martin Winkel
https://levelup.gitconnected.com/advanced-pytest-techniques-i-learned-while-contributing-to-pandas-7ba1465b65eb
1.22. pdb, Python REPL
1.22.1. pdb — The Python Debugger — Python 3 documentation
https://docs.python.org/3/library/pdb.html#pdbcommand-interact
Para no tener que usar IPython, alternativas:
try: from IPython import embed except ImportError: import code def embed(): vars = globals() vars.update(locals()) shell = code.InteractiveConsole(vars) shell.interact()
1.22.2. python -m asyncio
Esto crea un intérprete async
1.23. async Python
1.23.1. welcome - Python Concurrency with asyncio MEAP V10
1.23.2. Build Your Own Async - David Beazley explains the hows and whys of python’s asyncio from scratch
1.23.3. Sync vs. Async Python: What is the Difference? - miguelgrinberg.com
- Async
- asyncio with async/await
- Greenlets
- no async/await but also cooperative, releasing the GIL switches to another task if there is one(?)
1.24. Python Distributed MapReduce with Parallel Processing
Hay todo un ecosistema montado detras de pandas para soportar procesamientos distribuidos/paralelos
1.24.2. What is Ray? — Ray v2.0.0.dev0
Lib paralela de pandas que usa redis
1.24.3. RayOnSpark: Running Emerging AI Applications on Big Data Clusters with Ray and Analytics Zoo | by Jason Dai | riselab | Medium
Spark también
1.24.4. modin-project/modin: Modin: Speed up your Pandas workflows by changing a single line of code
Y modin te permite trabajar en paralelo con dataframes. Dask si quieres trabajar con dfs grandes en tu disco (para no cargarlos en memoria) y ray si quieres trabajar en un cluster de redis/spark o lo que sea que soporte ray
1.24.5. How to process a DataFrame with millions of rows in seconds
1.25. Python Alternative interpreters
1.25.1. Cinder: Instagram’s internal performance-oriented production version of CPython 3.8
1.25.2. Pyston v2.2: faster and open source (30% faster than stock Python)
1.25.3. OpenAI releases Triton: Python-like language for GPU programming
1.25.4. PyPy: Faster Python With Minimal Effort – Real Python
1.25.4.1. Faster Python with Guido van Rossum (on PyPy)
https://www.softwareatscale.dev/p/software-at-scale-34-faster-python
And if you take PyPy, it has always sounded like PyPy is sort of a magical solution that only a few people in the world understand how it works. And those people built that and then decided to do other things. And then they left it to a team of engineers to solve the real problems with PyPy, which are all in the realm of compatibility with extension modules. And they never really solved that.
1.25.5. pfalcon/pycopy: Pycopy - a minimalist and memory-efficient Python dialect. Good for desktop, cloud, constrained systems, microcontrollers, and just everything.
1.25.6. MicroPython - Python for microcontrollers
1.26. Hash of python function
[ ]Recursively get all functions called from a given function- A easier alternative is commit hash
# https://stackoverflow.com/questions/51901676/get-the-lists-of-functions-used-called-within-a-function-in-python import dis def list_func_calls(fn): funcs = [] bytecode = dis.Bytecode(fn) instrs = list(reversed([instr for instr in bytecode])) for (ix, instr) in enumerate(instrs): # https://docs.python.org/3/library/dis.html#opcode-CALL_FUNCTION if instr.opname in ("CALL_FUNCTION", "CALL_FUNCTION_KW", "CALL_FUNCTION_EX"): load_func_instr = instrs[ix + instr.arg + 1] funcs.append(load_func_instr.argval) return ["%d. %s" % (ix, funcname) for (ix, funcname) in enumerate(reversed(funcs), 1)]
1.27. Visualization
1.27.1. Matplotlib
1.27.1.1. Nicolas P. Rougier
1.27.1.3. Instalación de todos los backends
https://matplotlib.org/stable/users/explain/figure/backends.html#backends
pip install tk PyQt6 # Estos funcionan con pip
1.27.1.4. Trucos Matplotlib
import matplotlib.pyplot as plt plt.ion() # Interactive mode ON plt.rc('text', usetex=True) # Latex rendering plt.minorticks_on() # Needs to be set before calling plot.grid() plt.grid(True, which='both') plt.tick_params(axis='both', which='major', labelsize=20) # Plot tick size plt.tight_layout() # If xlabel gets cut off plt.xlabel('$\\lambda \\mathrm{ (nm)}$') plt.xlabel('$\\lambda \\text{ (nm)}$') # PETA fuertemente plt.xlabel('$\\lambda $\\text{ (nm)}') # Probar plt.title(r'Entrop\'ia') # renders to Entropía plt.title(r"$Regresi\'on$") # Renders to Regresión # Linear regression slope, intercept, r, prob2, see = scipy.stats.linregress(x, y) mx = x.mean() sx2 = ((x-mx)**2).sum() sd_intercept = see * np.sqrt(1./len(x) + mx*mx/sx2) sd_slope = see * np.sqrt(1./sx2)
- Cambiar el preámbulo de matplotlib
import matplotlib.pyplot as plt plt.rc('text', usetex=True) plt.rc('text.latex', preamble=r'\usepackage{amsmath} \usepackage{foo-name} `...') matplotlib.verbose.level = 'debug-annoying'
- Estilos de plots
plt.style.use('fivethirtyeight') plt.style.use('ggplot')
- Setup mínimo de tex para matplotlib
apt-get install texlive-base texlive texlive-fonts* apt-get install dvipng
1.27.1.5. animaciones
from matplotlib.animation import FuncAnimation from matplotlib.animation import writers Writer = writers['ffmpeg'] Writer = writers['ffmpeg_file'] # Para exportar muchos frames y no comerse la ram duration = 120 # En segundos fps = t_gridnum/duration if t_gridnum/duration > 25.0 else 25.0 # Mínimo 25fps writer = Writer(fps=fps) ani = FuncAnimation(fig, animate, init_func=init, frames=np.arange(len(times)), repeat=False, cache_frame_data=False) # Importante el cache_frame_data para mayor velocidad con vídeos de muchos frames
https://brushingupscience.com/2016/06/21/matplotlib-animations-the-easy-way/
Moviepy:
https://gitlab.com/celliern/scikit-fdiff/-/issues/7#note_204557752
1.28. numpy
1.28.1. PDEs
para ecuaciones en derivadas parciales por elementos finitos, skfdiff
(siempre que no sean deformaciones de sólidos, etc. que en teoría están mejor en sfepy)
- Interfaz muy sencilla
- Barra de progreso (weeee)
- Soporta como backend numpy o numba y paraleliza usando todos los cores
1.28.2. numpy
import numpy as np np.squeeze(array) # Elmina arrays tontos que suceden cuando np.array(algo) y algo ya es un array de numpy, o cuando un array # tiene elementos que son arrays unidimensionales en vez de números directamente. # Para detectarlo, la forma de resolverlo sin usar esto es algo de la forma: array = array[0] array = np.array([x[0] for x in array]) np.einsum('ij,jk->ik', A, B, C) # Permite indicar la estructura de índices con convenio de Einstein para no tenerla que adivinar con np.dot() # La descripción de indices es un str como primer parámetro y el resto son arrays de numpy # Varias condiciones lógicas sobre un array de numpy # Las condiciones no funcionan si se hacen sobre una lista ind = np.where((condicion1) & (condicion2) & . . . (condicionN)) np.memmap permite guardar arrays en disco sin que ocupen toda la memoria
1.28.2.1. Optimización
If you have slow loops in Python, you can fix it… until you can’t
np.einsumes un poco más rápido quenp.sumporque especificas los índices- Para aplicar funciones elemento a elemento en vez de con un
for, usarnp.fromiter, aunque si hay una versión “vectorizada por defecto” conlambdao similar, es lo más rápido. np.frompyfuncparece que vectoriza y además convierte enufunc, muy útil cuando una librería tiene una función que no soporta broadcasting (todavía no lo he probado)
https://stackoverflow.com/questions/35215161/most-efficient-way-to-map-function-over-numpy-array
np.memmappara cargar arrays en disco sin que ocupen espacio en memoria. Para tampoco cargarlos en memoria, hay que iterar sí o sí confor. Luego los tienes que cargar connp.lib.format.open_memmappor alguna razón extraña porque si no no te conserva el shape
1.29. Alternatives to CSV
1.29.1. Feather instead of CSV
1.29.2. Parquet instead of CSV
1.30. FastAPI, Uvicorn, Gunicorn…
1.30.1. Full guide on how to set up backend app with FastAPI (Python), async SQLAlchemy ORM and alembic with full project example
1.31. Optimización
1.31.1. Tensor contractions with numpy’s einsum function seem slow compared to simple code.
1.32. sympy
from sympy import * Sum(expr, (n, inicio, fin)) -> suma simbólica Sum(expr, (n, inicio, fin)).doit() -> hace la suma
1.33. Concurrencia
1.33.1. Introducción
Básicamente hay dos tipos de programas en los que puede interesar la
concurrencia:
- CPU-Bound: aplicaciones intensivas en CPU. Pierden tiempo porque podrían aprovechar todos los núcleos de la máquina.
- IO-Bound: aplicaciones que no son intensivas en CPU, pero que pierden tiempo esperando por resultados externos en los que podrían seguir haciendo cosas.
Como vamos a estar siempre limitados por el GIL, sólo va a haber un hilo ejecutándose en cada intérprete de Python (suele conincidir con un proceso, ver Has the Python GIL been slain? para más detalles).
Para aplicaciones IO-Bound nos vale perfectamente threading (es cooperativo, no preemptivo), ya que cuando una aplicación no hace nada porque está esperando a un resultado de IO, deja que se ejecute otra tarea.
Para aplicaciones CPU-Bound, hay que usar multiprocessing, pero también son útiles si el programa tiene alguna parte IO-Bound. El precio a pagar es que el inicio de un proceso y las comunicaciones entre ellos son más pesadas que en el caso de los hilos. Los intérpretes vendrían a estar en el medio.
1.33.1.1. Términos clave
- Operación atómica: conjunto de operaciones que se pueden realizar sin que ocurra un cambio de contexto (el OS salta a otro proceso)
- Sección crítica: sección de código en la que un proceso solicita acceso a recursos compartidos. No se debería ejecutar a la vez en varios procesos
- Deadlock: situación en la que dos o más procesos necesitan dos (o más) recursos para continuar y cada proceso posee uno.
- Livelock: situación en la que dos o más procesos cambian continuamente de estado en respuesta a los cambios de estados de otros procesos
- mutex: semáforo binario o lock que activa un proceso para que ese recurso no pueda ser accedido por ningún otro
- Condición de carrera: situación en la que los procesos compiten por acceder a un recurso compartido y el estado del programa depende de qué proceso gane la carrera
- Starvation: en general, situación en la que un procesos se queda sin trabajo que hacer. Se usa sobre todo cuando un proceso no se llega a ejecutar a pesar de estar siempre preparado: puede ocurrir si 2 procesos se alternan indefinidamente
1.33.1.2. Semáforos
1.33.1.3. Productor/Consumidor
1.33.1.4. Lectores/Escritores
1.33.1.5. La cena de los filósofos
1.33.1.6. Deadlock
- mutex
- no preemptivo
- hold and wait (un proceso sólo libera recursos cuando adquiere todos
los necesarios para seguir ejecutándose) - Espera circular (A quiere R1, R2 y tiene R1, B también quiere R1, R2
y tiene R2 -> Generalizado a n procesos)
1.33.3. Sistemas distribuidos y sincronización
1.33.3.1. Lamport timestamps
1.33.3.2. Vector clocks
1.33.3.3. Vector versions
1.33.4. Peligros
1.33.5. Bin packing problem
Cómo puedes agrupar los iterables de manera que todos los procesos tarden lo mismo?
python - multiprocessing: Understanding logic behind `chunksize` - Stack Overflow
- Código
def distribuir_paquetes_greedy(paquetes, num_contenedores): # Inicializar los contenedores con sumas acumuladas en cero contenedores = [[] for _ in range(num_contenedores)] sumas_contenedores = [0] * num_contenedores # Ordenar los paquetes de mayor a menor (esto suele mejorar el resultado en el enfoque greedy) paquetes_ordenados = sorted(paquetes, reverse=True) for paquete in paquetes_ordenados: # Encontrar el contenedor con la suma acumulada más pequeña indice_minimo = sumas_contenedores.index(min(sumas_contenedores)) # Asignar el paquete a ese contenedor contenedores[indice_minimo].append(paquete) # Actualizar la suma acumulada del contenedor sumas_contenedores[indice_minimo] += paquete # Calcular la diferencia entre la suma máxima y mínima de los contenedores diferencia = max(sumas_contenedores) - min(sumas_contenedores) return contenedores, diferencia # Ejemplo de uso paquetes = [10, 20, 30, 40, 50, 60] num_contenedores = 3 distribucion, diferencia = distribuir_paquetes_greedy(paquetes, num_contenedores) print("Distribución aproximada:", distribucion) print("Diferencia aproximada:", diferencia) import heapq def aproximar_diferencia_paquetes(paquetes, num_contenedores): # Inicializar los contenedores como una lista de sumas (inicialmente todas en 0) contenedores = [0] * num_contenedores # Usamos un heap para que los contenedores con menor suma siempre estén en el frente heapq.heapify(contenedores) # Ordenamos los paquetes en orden descendente paquetes.sort(reverse=True) for paquete in paquetes: # Extraemos el contenedor con la suma más baja menor_contenedor = heapq.heappop(contenedores) # Añadimos el paquete al contenedor con la menor suma menor_contenedor += paquete # Reinsertamos el contenedor actualizado en el heap heapq.heappush(contenedores, menor_contenedor) # Las sumas finales de los contenedores return contenedores, max(contenedores) - min(contenedores) # Ejemplo de uso paquetes = [10, 20, 30, 40, 50, 60] num_contenedores = 3 contenedores, diferencia = aproximar_diferencia_paquetes(paquetes, num_contenedores) print("Suma de paquetes en contenedores:", contenedores) print("Diferencia mínima aproximada:", diferencia) Este usa un heap que entiendo que será mas rápido
1.33.6. Go statement considered harmful
- Notes on structured concurrency, or: Go statement considered harmful — njs blog
- Go statement is like a parallel goto that may result in parallel unstructured programming if not used carefully
- Go statement is like a parallel goto that may result in parallel unstructured programming if not used carefully
1.33.7. Async/Await
1.34. Python logging
- python logging only to file - Stack Overflow
- The `FileLogger` class is a custom logging class for Python that extends the functionality of the built-in `logging.Logger` class. It provides the ability to log messages ONLY to a file and optionally to the console, with customizable file name, mode, log level, and formatter.
1.34.0.1. Log de todas las líneas (como set -x)
import sys import logging logging.basicConfig(format='%(asctime)s | %(levelname)s : %(message)s', level=logging.INFO, stream=sys.stdout) vars = dict() globs = dict() def distinct(x1, x2): try: return bool(x1 != x2) except ValueError: pass try: return bool((x1 != x2).any()) except ValueError: pass try: return bool((x1 != x2).any().any()) except ValueError: pass return False def diff(vars, vars2): diff_keys = set(vars2.keys()) - set(vars.keys()) same_keys = set(vars2.keys()).intersection(vars.keys()) vars = {k: vars2[k] for k in same_keys if distinct(vars2[k], vars[k])} vars.update({k: vars2[k]for k in diff_keys }) return vars def trace_func(frame, event, arg): global vars global globs # Obtén el nombre del archivo del frame actual filename = frame.f_globals.get("__file__") if filename is None: return # Normaliza la ruta para evitar problemas con diferencias en el formato filename = os.path.normpath(filename) # Define el directorio base de tu script base_dir = os.path.normpath(os.path.dirname(__file__)) # Comprueba si el archivo actual está dentro de tu directorio base if filename.startswith(base_dir): if event == 'line': co = frame.f_code func_name = co.co_name line_no = frame.f_lineno vars2 = frame.f_locals globs2 = frame.f_globals # Hace la diferencia de diccionarios para loguear sólamente lo que cambia diff_vars = diff(vars, vars2) diff_globs = diff(globs, globs2) if (len(diff_vars) > 0) or (len(diff_globs) > 0): logging.info(f'Tracing {func_name} at line {line_no}: vars: {diff_vars} globs: {diff_globs}') globs = frame.f_globals vars = frame.f_locals return trace_func sys.settrace(trace_func)
1.35. Dokuwiki
1.35.1. pip freeze
Según este issue, pip freeze ya no vale como método para volcar dependencias, hay que usar:
pip list --format=freeze
1.35.2. links
1.35.2.1. Libros
1.35.2.2. Docs generales
- https://treyhunner.com/2019/05/python-builtins-worth-learning/
Ordenados de más conocidos/usados a menos - https://docs.python.org/3/library/pdb.html
1.35.2.3. Benchmarking
- Faster lists in python Scripts para ver cómo escalan las distintas
estructuras de datos de python - Optimización en python del estilo: “es más rápido hacer X o Y?”
1.35.3. trucos
1.35.3.1. Python.h: No such file or directory
hdbscan/_hdbscan_tree.c:4:10: fatal error: Python.h: No such file or directory
4 | #include "Python.h"
sudo apt install python3-dev # o la versión necesaria
1.35.3.2. Conversión rápida de casi-json espaciado con pprint a json
import json from pprint import pprint # j = json.loads(...) with open('Almost.json', 'w') as f: pprint(j, f)
cat Almost.json | sed -e "s/'/\"/g" | sed -Ez 's/"\n[ ]*\"//g' | sed "s/None/null/g" | sed "s/False/false/g" | sed "s/True/true/g" > Full.json
1.35.3.3. Recorrer un directorio recursivamente
- glob is your friend
from glob import glob files = glob("/path/to/files/**/*.ext", recursive=True) # Con recursive=True matchea también /path/to/files/*.ext
1.35.3.4. Recargas dinámicas con pdb
Cuando pones un pdb a una web o lo que sea, hay que ejecutar stty sane después, porque si guardas y se recarga flask/django (ambas tienen un fswatcher que notifica de cambios en los archivos) se queda pillada la terminal y no coje los RET bien
1.35.3.5. Conversiones de fecha con pytz
El localize te añade
import pytz import datetime date_naive_in_local_tz = datetime.datetime.now() date_naive_in_utc = datetime.datetime.utcnow() local_tz = pytz.timezone("America/Bogota") # WHYYYYYY???? date_utc = local_tz.localize(date_naive_in_local_tz).astimezone(pytz.utc) date_local = date_naive_in_utc.replace(tzinfo=pytz.utc).astimezone(local_tz) date_utc_naive = date_utc.replace(tzinfo=None) date_local_naive = date_local.replace(tzinfo=None)
1.35.3.6. async debugging
python -m asyncio Te crea un intérprete async
# Cuando esto da el siguiente error: (Pdb) node.read_value() RuntimeWarning: coroutine 'Node.read_value' was never awaited # Hay que ejecutarlo así: (Pdb) async def a(node): return await node.read_value() asyncio.run(a(node)) (Pdb) asyncio.run(a(node))
1.35.3.7. python debugger (pdb) con múltiples líneas
interacten una consola de Pdb- https://docs.python.org/3/library/pdb.html#pdbcommand-interact
1.35.3.8. Trabajando con warnings
- Ignorar warnings
python -W ignore::DeprecationWarning -m module
https://docs.python.org/3/library/warnings.html#the-warnings-filter
para control más fino de los warnings
- Subir una warning a error
Si hay que importar el error de otra librería, hay que poner en el
código:
import warnings warnings.filterwarnings(action="error", category=np.ComplexWarning)
Así, cuando se lance un warning, podemos ver el Traceback y ver la línea
de nuestro código que causó el warning
1.35.3.9. debugging
from pdb import set_trace from IPython import embed # Sin colores, deja la terminal bien from IPython import start_ipython # Con colores, deja la terminal mal al salir . . . breakpoint(header=embed()) # Python 3.7+ en vez de set_trace # https://docs.python.org/3/library/functions.html#breakpoint
1.35.3.10. Sacar la traza cuando no hay excepción
# NO FUNCIONA BIEN? Creo que te imprime desde donde estás el traceback, no desde el error: import traceback; print("".join(traceback.format_stack())) # Estas sí que funcionan import traceback; import sys; traceback.print_exc(); traceback.print_exception(*sys.exc_info())
import sys import traceback try: raise TypeError("Oups!") except Exception as err: try: raise TypeError("Again ??") except: pass # Esta imprime el traceback desde donde estás, no el error print("".join(traceback.format_stack())) # Esta llega sólamente hasta el raise, no te muestra el error como tal (por ejemplo si el error es una plantilla, sabes qué valores toman los datos) traceback.print_tb(err.__traceback__) print(err) traceback.print_exc() traceback.print_exception(*sys.exc_info())
Si estás en Jupyter, parece que no funciona del todo bien?
from IPython import get_ipython ipython = get_ipython() ipython.magic("tb Verbose")
1.35.4. memoryview
- memoryview
copias más rápidas de memoria a bajo nivel
1.35.5. listas
1.35.5.1. operaciones matriciales sin numpy
def transpose(M): return list(map(list, zip(*M))) def dot(M, v): return [sum([m*x for m, x in zip(row, v)]) for row in M]
1.35.5.2. list comprehension
In : [i for i in range(20) if i % 3 > 0] # Condicionales Out: [1, 2, 4, 5, 7, 8, 10, 11, 13, 14, 16, 17, 19] In : [(i, j) for i in range(2) for j in range(3)] # Dobles índices Out: [1, 2, 4, 5, 7, 8, 10, 11, 13, 14, 16, 17, 19] In : [val if val % 2 else -val for val in range(20) if val % 3] Out: [1, -2, -4, 5, 7, -8, -10, 11, 13, -14, -16, 17, 19] In : {a % 3 for a in range(1000)} # set filtra valores únicos Out: {0, 1, 2} In : {n:n**2 for n in range(6)} # diccionario Out: {0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25} In : (n**2 for n in range(12)) # crea un generador (iterador) Out: <generator object <genexpr> at 0x7f92cc317138>
1.35.5.3. dict comprehension
Los if van entre paréntesis en cada expresión para clave y valor. Si no hay un if en clave o en valor, no son necesarios paréntesis
{(k if not np.isnan(v) else k + "_nan"): (v if not np.isnan(v) else None) for k, v in sample_dictionary.items()}
{k: (v if not np.isnan(v) else None) for k, v in sample_dictionary.items()}
1.35.5.4. for con índice o varios objetos
# Iterar sobre lista y con índice al mismo tiempo: for index, element in enumerate(object[, start=0]): # Iterar sobre varias listas a la vez: for x1, x2, ..., xN in zip(list1, list2, ..., listN): # Combinando las dos: for index, elementlist in enumerate(zip(list1, list2, ... listN)):
1.35.6. collections
1.35.6.1. namedtuple
from collections import namedtuple Features = namedtuple('Features', ['age', 'gender', 'name']) row = Features(age=22, gender='male', name='Alex') # row.age, row.gender, row.name
1.35.6.2. Counter
from collections import Counter ages = [22, 22, 25, 25, 30, 24, 26, 24, 35, 45, 52, 22, 22, 22, 25, 16, 11, 15, 40, 30] value_counts = Counter(ages) import numpy as np np.histogram(ages, bins=np.max(ages)-np.min(ages)) # Es más eficiente para len(ages) >~ 1000
1.35.7. slices
Para dar un nombre más user-friendly cuando estamos haciendo un slice, podemos hacer: TIME = slice(0, 10) RAIN = slice(20, 40) df[TIME] df[RAIN] así evitamos harcodear slices con números mágicos: df[0:10], df[20:40]
1.35.8. print, f-strings, formato
"Hello, {}. You are {}.".format(name, age), "Hello, {1}. You are {0}.".format(age, name) "Hello, {name}. You are {age}.".format(name="Julian", age=22) # También funciona con diccionarios: person = {'name': 'Eric', 'age': 74} "Hello, {name}. You are {age}.".format(**person) "{}{}{}{}".format(numbers=*nlist) # También se pueden desempacar listas # Desde python 3.6, f-strings. Se interpreta como código lo de dentro de {} f"Hello, {name}. You are {age}." f"{2 * 37}"
1.35.8.1. Formato printf dentro de f-strings
f'{a:1.2f}+{b:1.2f}j' f'{a=}' # En python 3.8, es equivalente a poner f'a={a}'
print (blablabla, end“\r”)= vuelve al principio de la línea y
sobrescribe lo anterior
1.35.9. map, filter, reduce
- Antes de usar list comprehension, preguntarse si se puede hacer lo mismo con
map
list comprehension
1.35.9.1. map
Usar map con métodos de una clase
from operator import methodcaller map(methodcaller('some_method'), some_object))
1.35.10. lambda
1.35.10.1. lambdas multilínea
PELIGRO USAR CON MODERACIÓN
hello_world = lambda x: ( [print("Hello world!"), globals().update({'var':3+2}), # Para crear variables print("Your name is "+x)] )[-1] hello_world("Julian")
# Nuevo en python 3.8 func = lambda x: ( # Se puede asignar con := # Las variables creadas tienen ámbito local y := 0, ( y := y + i for i in range(0, x)), y)[-1] y = func(101) print(y) # 5050
1.35.11. Diccionarios
- Los diccionarios permiten cualquier objeto como clave. Internamente
se generan las claves conhash(key), con lo cual cualquier cosa que
aceptehashes una clave válida.
1.35.11.1. Diccionarios con valor por defecto
mydict.get('key', default_value) # Devuelve mydict['key'] si existe, y si no, default_value mydict.setdefault('key', default_value) # Si 'key' está vacía, crea una nueva entrada con default_value
1.35.11.2. Darle la vuelta (reverse) un dict
mydict_inv = dict(map(reversed, mydict.items()))
1.35.11.3. Diccionarios como switch
value = { 'a': 1, 'b': 2, 'c': 3, . . . }.get(x, default_value)
Como los diccionarios se puede modificar, podemos modificar el “switch”
en tiempo de ejecución, a diferencia de un switch sintáctico.
# De nuevo en python 3.8 podemos hacer asignaciones value = {'a': 7, 'b': 6 if True else 0, 'c': [y :=0, [y := y+x for x in range(0, 101)]][-1][-1] }.get('c', 0) print(value) # 5050
1.35.11.4. unir diccionarios
ab = {**a, **b} # Si tienen una clave común, prevalece el valor de b
1.35.11.5. crear un dict a partir de listas
Si tenemos dos listas, a y b de la misma longitud y queremos hacer
diccionario con el siguiente formato:
# {a[0]:b[0], a[1]:b[1], a[2]:b[2], ..., a[n]:b[n]} dict(zip(a, b))
1.35.12. funciones
1.35.12.1. *args, **kwargs y unpacking
- Antes de usar list comprehension, preguntarse si se puede hacer lo mismo desempacando
def myfunc(x, y, z): print(x, y, z) tuple_vec = (1, 0, 1) dict_vec = {'x': 1, 'y': 0, 'z': 1} myfunc(*tuple_vec) # 1, 0, 1 myfunc(**dict_vec) # 1, 0, 1
https://www.agiliq.com/blog/2012/06/understanding-args-and-kwargs/
1.35.12.2. funciones como argumentos
# Functions are first-class citizens in Python: # Functions can be passed as arguments to other functions, # returned as values from other functions, and # assigned to variables and stored in data structures.
1.35.12.3. Recargar módulos y funciones
import sys from importlib import reload if sys.modules.get('module') is not None: reload(sys.modules['module']) from module import function
1.35.13. Clases
1.35.13.1. magic methods
- excluding operators
Category Method names String/bytes representation __repr__, __str__, __format__, __bytes__Conversion to number __abs__, __bool__, __complex__, __int__, __float__, __hash__, __index__Emulating collections __len__, __getitem__, __setitem__, __delitem__, __contains__Iteration __iter__, __reversed__, __next__Emulating callables __call__Context management __enter__, __exit__Instance creation and destruction __new__, __init__, __del__Attribute management __getattr__, __getattribute__, __setattr__, __delattr__, __dir__Attribute descriptors __get__, __set__, __delete__Class services __prepare__, __instancecheck__, __subclasscheck__ - operators
Category Method names Unary numeric operators __neg__ -, __pos__ +, __abs__ abs()Rich comparison operators __lt__ >, __le__ <, eq=, __ne__ !, gt >, ge >==Arithmetic operators %%add +, sub -, mul *, truediv /, floordiv //, mod %,__divmod__divmod() , pow ** or pow(), round round()%%’’Reversed arithmetic operators __radd__, __rsub__, __rmul__, __rtruediv__, __rfloordiv__, __rmod__,__rdivmod__, __rpow__Augmented assignment arithmetic operators __iadd__, __isub__, __imul__, __itruediv__, __ifloordiv__, __imod__, __ipow__Bitwise operators =__invert__ ~, lshift <<, rshift >>, and &, or , xor ^= Reversed bitwise operators __rlshift__, __rrshift__, __rand__, __rxor__, __ror__Augmented assignment bitwise operators __ilshift__, __irshift__, __iand__, __ixor__, __ior__ - getattr vs getattribute
- getattr
sólo se llama cuando no se encuentra el atributo. El método que se
llama siempre si se encuentra el atributo o no es
getattribute
- getattr
1.35.14. sequences
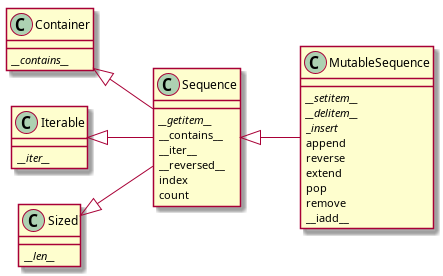
left to right direction
class Container {
{method} //__contains__//
}
class Iterable {
{method} //__iter__//
}
class Sized {
{method} //__len__//
}
class Sequence {
{method} //__getitem__//
{method} __contains__
{method} __iter__
{method} __reversed__
{method} index
{method} count
}
class MutableSequence {
{method} //__setitem__//
{method} //__delitem__//
{method} _//insert//
{method} append
{method} reverse
{method} extend
{method} pop
{method} remove
{method} __iadd__
}
Container <|-- Sequence
Iterable <|-- Sequence
Sized <|-- Sequence
Sequence <|-- MutableSequence
1.35.14.1. sort, sorted
mylist.sort() # Modifica inplace mysortedlist = sorted(mylist) # Devuelve una copia ordenada
El algoritmo de ordenación de Python es Timsort, un algoritmo que es estable (los elementos que ya estaban ordenados mantienen su orden relativo)
1.35.14.2. bisect
Búsqueda binaria en una lista ordenada para buscar o insertar en la posición correcta.
1.35.15. resumen
Falta por migrar