data science
Table of Contents
- 1. data science
- 1.1. Awesome data science
- 1.2. https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
- 1.3. Seven states of randomness - Wikipedia
- 1.4. Resources
- 1.5. Want to know how to turn change into a movement? - Gapingvoid
- 1.6. Forward problems vs inverse problems: It’s easier to validate than to generate
- 1.7. The Strong ML Hypothesis
- 1.8. Thinking about High-Quality Human Data | Lil’Log
- 1.9. Evolutionary Tree of LLMs Lineage Genealogy of models
- 1.10. data science links
- 1.10.1. links
- 1.10.2. Visualización de datos
- 1.10.3. k-means y Voronoi
- 1.10.4. DBSCAN
- 1.10.5. Local outlier factor - Wikipedia (Basado en densidad como DBSCAN)
- 1.10.6. geocosas
- 1.10.7. https://github.com/easystats/ R repos
- 1.10.8. An intuitive, visual guide to copulas — While My MCMC Gently Samples
- 1.10.9. Generación de datos
- 1.10.10. Structural Temporal Series
- 1.10.11. The Artificial Intelligence Wiki | Pathmind
- 1.11. Bootstrapping
- 1.12. Taguchi Matrix / Taguchi Arrays
- 1.13. Common Statistical Tests Are Linear Models
- 1.14. Links
- 1.15. Scaling laws in complex systems
- 1.16. PCA & SVD & EFA
- 1.17. Wavelets
- 1.18. Bayesian
- 1.19. LDA
- 1.20. NLP
- 1.20.1. Gensim: Topic modelling for humans
- 1.20.2. A Beginner’s Guide to Word2Vec and Neural Word Embeddings | Pathmind
- 1.20.3. Word embedding - Wikipedia
- 1.20.4. The Illustrated Word2vec – Jay Alammar – Visualizing machine learning one concept at a time.
- 1.20.5. Linguistic Regularities in Sparse and Explicit Word Representations - ACL Anthology word2vec more advanced
- 1.20.6. Latent Dirichlet allocation - Wikipedia
- 1.20.7. Latent semantic analysis - Wikipedia
- 1.20.8. Cognition, Convexity, and Category Theory | The n-Category Café
- 1.20.9. Vectorization Techniques in NLP [Guide]
- 1.20.10. An Introduction to Unsupervised Topic Segmentation with Implementation in Python | Naveed Afzal
- 1.21. Vector Search
- 1.22. Transformers
- 1.23. Diffusion models
- 1.24. Regularization
- 1.25. MoE
- 1.26. Noise 1/f fractional gaussian / fractional brownian motion
- 1.27. Notebooks
- 1.28. Artificial Intelligence
- 1.29. Softmax vs Logistic
- 1.30. Softmedian
- 1.31. Dive into Deep Learning — Dive into Deep Learning 1.0.0-beta0 documentation
- 1.32. Metrics & Scoring
- 1.32.1. Types of Metrics
- 1.32.2. Directional Statistics
- 1.32.3. Diversity index
- 1.32.4. Similarity measure
- 1.32.5. Fréchet Distances
- 1.32.6. Fréchet mean - Wikipedia
- 1.32.7. Statistical distance & Generalized metrics
- 1.32.8. Correlations
- 1.32.9. Hamming distance - Wikipedia
- 1.32.10. Kendall tau distance - Wikipedia
- 1.32.11. Spearman’s rank correlation coefficient - Wikipedia
- 1.33. Divergences
- 1.34. Metric Space vs Topological Space
- 1.35. Entropies
- 1.36. Alternative languages for data
- 1.37. Non-Euclidean Statistics
- 1.37.1. Thoughts on Riemannian metrics and its connection with diffusion/score matching [Part I] | Terra Incognita
- 1.37.2. The geometry of data: the missing metric tensor and the Stein score [Part II] | Terra Incognita
- 1.37.3. https://en.wikipedia.org/wiki/Directional_statistics
- 1.37.4. https://en.wikipedia.org/wiki/Complex_random_variable
- 1.37.5. The Fréchet Mean and Statistics in Non-Euclidean Spaces - heiDOK
- 1.37.6. Into the Wild: Machine Learning In Non-Euclidean Spaces · Stanford DAWN
- 1.37.7. https://en.wikipedia.org/wiki/Directional_statistics
- 1.37.8. hyperbolic neural networks
- 1.37.9. Maria Alonso-Pena - Google Académico - Circular mean
- 1.38. Relational Machine Learning
- 1.39. Machine Learning
- 1.40. DataForScience/Causality
- 1.41. Are Observational Studies of Social Contagion Doomed? - YouTube
- 1.41.1. What We (Should) Agree On
- 1.41.2. Social Influence Exists and Matters
- 1.41.3. Homophily Exists and Matters
- 1.41.4. Selection vs. Influence, Homophily vs. Contagion
- 1.41.5. How Do We Identify Causal Effects from Observations?
- 1.41.6. Good Control, Bad Control
- 1.41.7. Why Influence is Unidentified from Observations
- 1.41.8. Endogenous Selection Blas
- 1.41.9. A Bit More on Lags
- 1.41.10. A Bit More on Propensity Scores
- 1.41.11. A Bit More on Asymmetry
- 1.41.12. A Bit More on Parametric Modeling Assumptions
- 1.41.13. OK, What About Instruments?
- 1.41.14. Friends of Friends Are Not Instruments
- 1.41.15. Summing Up the Negative Part
- 1.41.16. Richer Measurements
- 1.41.17. Graph Clustering
- 1.41.18. Causal Inference: What If (the book) | Miguel Hernan’s Faculty Website | Harvard T.H. Chan School of Public Health
- 1.42. Reading Group: Advanced Data Analysis by Prof. Cosma Shalizi - YouTube
- 1.43. AI Safety
- 1.44. Network analysis
- 1.45. How to Choose a Feature Selection Method For Machine Learning
- 1.46. https://en.wikipedia.org/wiki/Mark_d'Inverno
1. data science
1.1. Awesome data science
1.3. Seven states of randomness - Wikipedia
https://en.wikipedia.org/wiki/Seven_states_of_randomness
- Proper mild randomness: short-run portioning is even for N = 2, e.g. the normal distribution
- Borderline mild randomness: short-run portioning is concentrated for N = 2, but eventually becomes even as N grows, e.g. the exponential distribution with rate λ = 1 (and so with expected value 1//λ/ = 1)
- Slow randomness with finite delocalized moments: scale factor increases faster than q but no faster than \[ \(\sqrt[w]{q}\) \], w < 1
- Slow randomness with finite and localized moments: scale factor increases faster than any power of q, but remains finite, e.g. the lognormal distribution and importantly, the bounded uniform distribution (which by construction with finite scale for all q cannot be pre-wild randomness.)
- Pre-wild randomness: scale factor becomes infinite for q > 2, e.g. the Pareto distribution with α = 2.5
- Wild randomness: infinite second moment, but finite moment of some positive order, e.g. the Pareto distribution with \[ \(\alpha \leq 2\) \]
- Extreme randomness: all moments are infinite, e.g. the log-Cauchy distribution
1.4. Resources
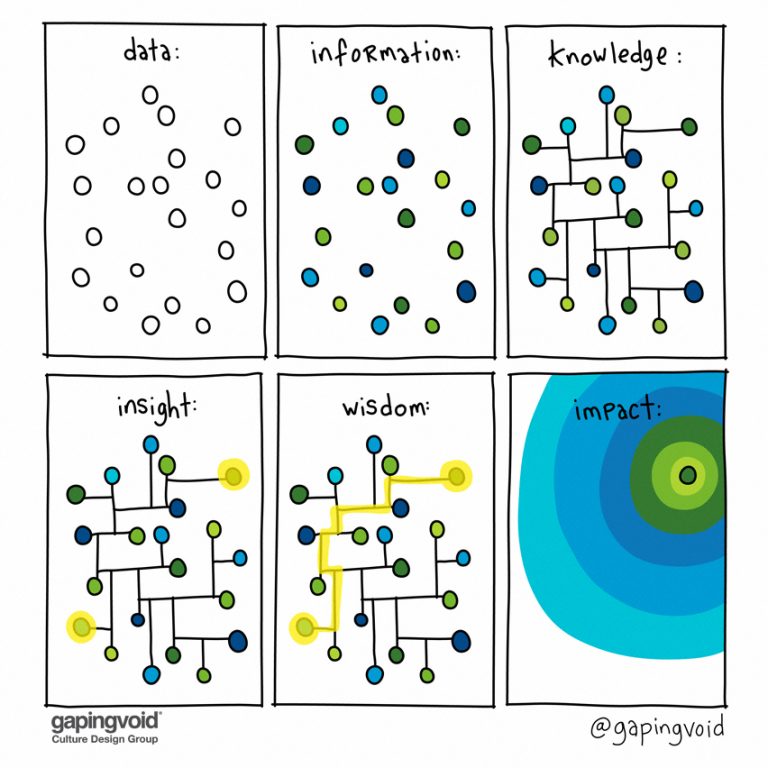
1.6. Forward problems vs inverse problems: It’s easier to validate than to generate
Es más fácil etiquetar que inferir, o es más fácil validar si algo está bien hecho que hacerlo/generarlo. Por lo tanto, también es más fácil elegir cuál es la mejor alternativa entre una lista cerrada que generar “de cero”
Forward problem: aplicar la fórmula de la gravedad (~deducción?)
Inverse problem: proponer una fórmula para la gravedad (~inducción?)
https://en.wikipedia.org/wiki/Inverse_problem
Corolario para LLM: es más sencillo para una LLM elegir la mejor opción entre dos opciones (que se le pasan como texto) que generar la mejor opción (y que elegir de primeras entre múltiples opciones)
El aprendizaje supervisado es una “herramienta de aumentado matemático”: te permite desplegar mayores habilidades matemáticas de las que tienes, porque las está generando el modelo y tú simplemente le pasas ejemplos
- Neural networks as non-leaky mathematical abstraction — LessWrong
[2111.04731] Survey of Deep Learning Methods for Inverse Problems
In principle, every deep learning framework could be interpreted as solving some sort of inverse problem, in the sense that the network is trained to take measurements and to infer, from given ground truth, the desired unknown state
Machine Learning convierte un inverse problem en un forward problem
https://en.wikipedia.org/wiki/Manifold_hypothesis
https://en.wikipedia.org/wiki/Whitney_embedding_theorem
1.7. The Strong ML Hypothesis
1.7.1. The Bitter Lesson
1.10. data science links
1.10.1. links
- https://github.com/conordewey3/DS-Career-Resources
- Data Science Course Repositories
- http://vrl.cs.brown.edu/color Paletas de color con distancia perceptual
- Tipos de visualizaciones menos conocidas
- Ejemplos de todas las gráficas
- Visualización de vientos y fuentes de datos meteorológicas
- Chuleta de redes neuronales
- Chuleta de redes neuronales (Fuente original)
- DynamicMath Interactive Mathematical Applets & Animations
- The danger of AI is weirder than you think
IA explicada, por qué no funciona porque intenta “hacer trampas” porque no le has definido bien lo que es “hacer trampas” - Neural networks and deep learning A visual proof that neural nets can compute any function
- [1908.03682] Natural-Logarithm-Rectified Activation Function in Convolutional Neural Networks
- Machine learning’s crumbling foundations (Doing Data Science with bad data) https://link.medium.com/ddGMY1uRVib
1.10.2. Visualización de datos
1.10.3. k-means y Voronoi
1.10.4. DBSCAN
- https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/
- https://en.wikipedia.org/wiki/DBSCAN#Parameter_estimation
- OPTICS algorithm - Wikipedia
Its basic idea is similar to DBSCAN, but it addresses one of DBSCAN’s major weaknesses: the problem of detecting meaningful clusters in data of varying density. To do so, the points of the database are (linearly) ordered such that spatially closest points become neighbors in the ordering. Additionally, a special distance is stored for each point that represents the density that must be accepted for a cluster so that both points belong to the same cluster. This is represented as a dendrogram.
1.10.4.1. Centrality Algorithms- A bird"s eye view - Part 1
https://www.reddit.com/r/programming/comments/rztvve/centrality_algorithms_a_birds_eye_view_part_1/
There are many different centrality algorithms, but most of them fall into one of three categories: degree, betweenness, and closeness.
Degree centrality is simply the number of connections a node has. Betweenness centrality measures how often a node is the shortest path between two other nodes. Closeness centrality measures how close a node is to all other nodes.
1.10.5. Local outlier factor - Wikipedia (Basado en densidad como DBSCAN)
1.10.6. geocosas
1.10.7. https://github.com/easystats/ R repos
- report Automated reporting of objects in R
- parameters Computation and processing of models’ parameters
- performance Models’ quality and performance metrics (R2, ICC, LOO, AIC, BF, …)
- modelbased Estimate effects, contrasts and means based on statistical models
- insight Easy access to model information for various model objects
- effectsize Compute and work with indices of effect size and standardized parameters
- easystats The R easystats-project
- datawizard Magic potions to clean and transform your data
- bayestestR Utilities for analyzing Bayesian models and posterior distributions
- see Visualisation toolbox for beautiful and publication-ready figures
- correlation Methods for Correlation Analysis
- circus Contains a variety of fitted models to help the systematic testing of other packages
- blog The collaborative blog
1.10.8. An intuitive, visual guide to copulas — While My MCMC Gently Samples
1.10.9. Generación de datos
1.10.10. Structural Temporal Series
Temporal Series on continuous time
https://structural-time-series.fastforwardlabs.com/
https://en.wikipedia.org/wiki/Ornstein%E2%80%93Uhlenbeck_process → AR(1) process
1.11. Bootstrapping
1.11.1. Bootstrap is better than p-values
https://link.medium.com/ROYrhtRb7lb
Once you start using the Bootstrap, you’ll be amazed at its flexibility. Small sample size, irregular distributions, business rules, expected values, A/B tests with clustered groups: the Bootstrap can do it all!
1.11.2. https://www.kdnuggets.com/2017/06/7-techniques-handle-imbalanced-data.html
Undersampling in Python
g = (df.groupby('categorical_col')) balanced = g.apply(lambda x: x.sample(g.size().min()).reset_index(drop=True))
1.12. Taguchi Matrix / Taguchi Arrays
1.13. Common Statistical Tests Are Linear Models
Concerning the teaching of “non-parametric” tests in intro-courses, I think that we can justify lying-to-children and teach “non-parametric”“ tests as if they are merely ranked versions of the corresponding parametric tests. It is much better for students to think “ranks!” than to believe that you can magically throw away assumptions. Indeed, the Bayesian equivalents of “non-parametric”” tests implemented in JASP literally just do (latent) ranking and that’s it. For the frequentist “non-parametric”" tests considered here, this approach is highly accurate for N > 15.
«With non parametric you can have a monotonic relation between varaibles instead of a linear one»
- Assumption of Normality
- Generalized linear model - Wikipedia
- Quantile regression - Wikipedia predict the median instead of the mean
- Edge-preserving smoothing - Wikipedia → median is edge-preserving
- Spearman’s rank correlation coefficient - Wikipedia
1.14. Links
1.14.1. Moving from Statistics to Machine Learning, the Final Stage of Grief
1.14.2. Computer vision
1.14.3. Bayesian statistics and complex systems complex_systems
https://link.medium.com/rQ2Le9gxvcb
This (frequentist) might work for any very simple experiment, but it is fundamentally against Cohen & Stewart’s (1995) ideas which think of natural systems, hence a higher level of complexity than simple experiments comparable to rolling dices. They believe that systems can change over time, regardless of anything that happened in the past, and can develop new phenomena which have not been present to-date. This point of argumentation is again very much aligned with the definition of complexity from a social sciences angle (see emergence).
1.14.4. AI Agents are not Artists
1.16. PCA & SVD & EFA
SVD: non-square matrices
1.16.2. PCA and SVD explained with numpy
1.17. Wavelets
- [1208.4611] Human Time-Frequency Acuity Beats the Fourier Uncertainty Principle
- Ingrid Daubechies: Wavelet bases: roots, surprises and applications - YouTube
Yves Meyer, Stefan Meyer wavelet synthesis (1980s)
John Klauder, Alexandre Grossman & Thierry Paul (Squeezed States)
→ - Yves Meyer: restoring the role of mathematics in signal and image processing
- Fundamental Papers in Wavelet Theory
- The Haar wavelet is like a decision tree
- Least-squares spectral analysis - Wikipedia
- Linear canonical transformation - Wikipedia
- Wavelets: a mathematical microscope - YouTube
- Fractal Fract | Free Full-Text | A Quantum Wavelet Uncertainty Principle
- Books on wavelets
- time frequency - Wavelet Scattering explanation? - Signal Processing Stack Exchange
- Scale space - Wikipedia
- Scale-space axioms - Wikipedia
- Log Gabor filter - Wikipedia
- Gabor wavelet - Wikipedia
Minimize uncertainty relation shipes, like coherent states
1.19. LDA
Linear discriminant analysis - Wikipedia
is a generalization of Fisher’s linear discriminant, a method used to find a linear combination of features that characterizes or separates two or more classes of objects or events. The resulting combination may be used as a linear classifier, or, more commonly, for dimensionality reduction before later classification.
LDA is closely related to analysis of variance (ANOVA) and regression analysis, which also attempt to express one dependent variable as a linear combination of other features or measurements.
However, ANOVA uses categorical independent variables and a continuous dependent variable, whereas discriminant analysis has continuous independent variables and a categorical dependent variable.
Logistic regression and probit regression are more similar to LDA than ANOVA is, as they also explain a categorical variable by the values of continuous independent variables.
These other methods are preferable in applications where it is not reasonable to assume that the independent variables are normally distributed, which is a fundamental assumption of the LDA method.
LDA is also closely related to principal component analysis (PCA) and factor analysis in that they both look for linear combinations of variables which best explain the data.
LDA explicitly attempts to model the difference between the classes of data.
PCA, in contrast, does not take into account any difference in class, and factor analysis builds the feature combinations based on differences rather than similarities.
Discriminant analysis is also different from factor analysis in that it is not an interdependence technique: a distinction between independent variables and dependent variables (also called criterion variables) must be made.
LDA works when the measurements made on independent variables for each observation are continuous quantities. When dealing with categorical independent variables, the equivalent technique is discriminant correspondence analysis.
1.19.0.1. Latent Dirichlet allocation - Wikipedia
1.20. NLP
1.20.3. Word embedding - Wikipedia
1.20.4. The Illustrated Word2vec – Jay Alammar – Visualizing machine learning one concept at a time.
1.20.5. Linguistic Regularities in Sparse and Explicit Word Representations - ACL Anthology word2vec more advanced
1.20.9. Vectorization Techniques in NLP [Guide]
Bag of Words
Count occurrences of a word
Example:
from sklearn.feature_extraction.text import CountVectorizer cv = CountVectorizer(ngram_range=(2,2)) sents = ['coronavirus is a highly infectious disease', 'coronavirus affects older people the most', 'older people are at high risk due to this disease'] X = cv.fit_transform(sents) X = X.toarray()
TF-IDF (Term Frequency–Inverse Document Frequency)
\begin{equation*} TF = \frac{\text{Frequency of word in a document}}{\text{Total number of words in that document}} \end{equation*} \begin{equation*} DF = \frac{\text{Documents containing word W}}{\text{Total number of documents}} \end{equation*} \begin{equation*} IDF = \log \left( \frac{\text{Documents containing word W}}{\text{Total number of documents}} \right) \end{equation*}
Corrects over-counting of articles, prepositions and conjuctions
Example:
from sklearn.feature_extraction.text import TfidfVectorizer tfidf = TfidfVectorizer() transformed = tfidf.fit_transform(sents) import pandas as pd df = pd.DataFrame(transformed[0].T.todense(), index=tfidf.get_feature_names(), columns=["TF-IDF"]) df = df.sort_values('TF-IDF', ascending=False)
- Word2vec - Wikipedia
1.21. Vector Search
- currentslab/awesome-vector-search: Collections of vector search related libraries, service and research papers
- [2403.05440] Is Cosine-Similarity of Embeddings Really About Similarity?
Embeddings are optimized for next-token prediction, not for recommendation per se
- Lecture 12: Embedding models
- Embeddings: What they are and why they matter
1.22. Transformers
1.23. Diffusion models
1.24. Regularization
1.25. MoE
1.26. Noise 1/f fractional gaussian / fractional brownian motion
1.27. Notebooks
1.28. Artificial Intelligence
1.29. Softmax vs Logistic
1.30. Softmedian
- The softmedian
- max function is the limit of the softmax when the temperature goes to zero
1.32. Metrics & Scoring
1.32.1. Types of Metrics

- https://en.m.wikipedia.org/wiki/Jaccard_index
- https://en.m.wikipedia.org/wiki/Simple_matching_coefficient
- https://en.m.wikipedia.org/wiki/Minkowski_distance
- https://en.m.wikipedia.org/wiki/Chebyshev_distance
- https://en.m.wikipedia.org/wiki/S%C3%B8rensen%E2%80%93Dice_coefficient
- K-L divergence
- Levenhstein distance
- Edit Distance
1.32.1.1. Distance between spatio-temporal series
- User Guide — tslearn stable documentation
Dynamic Time Warping Detect underdog stocks to buy during pandemic using Dynamic Time Warping
Longest Common Subsequence
Kernel Methods - GPS Trajectories Clustering in Python
- The windowed scalogram difference: a novel wavelet tool for comparing time series
1.32.1.2. Correlations can also be metrics
The trick is to replace what is usually the mean (sometimes the median) with an estimator from a model
- https://en.wikipedia.org/wiki/Pearson_correlation_coefficient
\[ \rho = \frac{(\vec{x} - \langle{\vec{x}}\rangle) \cdot (\vec{y} - \hat{\vec{y}})}{\sqrt{[(\vec{y} - \hat{\vec{y}}) \cdot (\vec{y} - \hat{\vec{y}})] [(\vec{x} - \langle{\vec{x}}\rangle) \cdot (\vec{x} - \langle{\vec{x}}\rangle)]}} \sim \frac{Cov(\vec{x}, \vec{y})}{\sigma(\vec{x}) \sigma(\vec{y})}\;\;\text{ if $\hat{\vec{y}}$ were $\langle\vec{y}\rangle$}\]
https://en.wikipedia.org/wiki/Covariance
The Pearson distance is \[ d = 1 - \rho \] or better \[ d = \frac{1-\rho}{2} \] with \[ 0 \le d \le 1 \] - https://en.wikipedia.org/wiki/Spearman%27s_rank_correlation_coefficient nonparametric measure of rank correlation (statistical dependence between the rankings of two variables). It assesses how well the relationship between two variables can be described using a monotonic function.
- https://en.wikipedia.org/wiki/Coefficient_of_determination
- https://en.wikipedia.org/wiki/Pseudo-R-squared
The coefficient of determination can be thought of as a ratio of the variance between any two models, and this can be interpreted as 1 minus the ratio of each residual vector.
Usually the base model is the mean or the median: \[ \hat{y}_0 = \langle y \rangle \]
Similarity between models:
There has to be some type of bound \[ {\sum (y - \hat{y}_1)^2} \le {\sum (y - \hat{y}_0)^2} \]. Then we can interpret: \[ R^2 = 1 - \frac{\sum (y - \hat{y}_1)^2}{\sum (y - \hat{y}_0)^2} = 1 - \frac{(\vec{y} - \hat{\vec{y}}_1) \cdot (\vec{y} - \hat{\vec{y}}_1)}{(\vec{y} - \hat{\vec{y}}_0) \cdot (\vec{y} - \hat{\vec{y}}_0)} \]
as similarity between model \[\hat{y}_1\] and \[\hat{y}_0\]. If \[R^2\] is close to 0, then the variance of model \[\hat{y}_1\] is close to the variance of model \[\hat{y}_0\]. If \[R^2\] is close to 1, then the model \[\hat{y}_1\] has lower variance than \[\hat{y}_0\]
Note that \[\chi^2\] is the quotient of variances
Also when comparing 2 regressions you can use a F-test (The Elements of Statistical Learning Eq. 3.13), comparing the RSS (Residual Square Sum = \[\sum (y - \hat{y})^2 \]) between two regression models:
\[ F = \frac{(RSS_0 - RSS_1)/(p_1 - p_0)}{RSS_1/(N-p_1-1)}\]
With a distribution of \[ F_{{p_1 - p_0},{N-p_1-1}} \] under some assumptions (see citation above)
https://sites.duke.edu/bossbackup/files/2013/02/FTestTutorial.pdf this can be generalized into any model with degrees of freedom:
\[ F = \frac{(RSS_0 - RSS_1)/(df_0 - df_1)}{RSS_1/df_1}\]
With a distribution of \[ F_{{df_0 - df_1},{df_1}} \] under those assumptions
1.32.1.3. Integral of a product as dot product (inner product)
\[\vec{f} \cdot \vec{g} = \int_a^b{f(t) \cdot g(t)\:dt} = \sum_i^N f_i \cdot g_i \Delta t_i\]
1.32.2. Directional Statistics
1.32.3. Diversity index
1.32.4. Similarity measure
1.32.5. Fréchet Distances
1.32.6. Fréchet mean - Wikipedia
1.32.8. Correlations
- How to combine R-squared: https://en.wikipedia.org/wiki/Fisher_transformation
- The Search for Categorical Correlation | by Shaked Zychlinski | Towards Data Science
-
import scipy.stats as ss def cramers_v(x, y): confusion_matrix = pd.crosstab(x,y) chi2 = ss.chi2_contingency(confusion_matrix)[0] n = confusion_matrix.sum().sum() phi2 = chi2/n r,k = confusion_matrix.shape phi2corr = max(0, phi2-((k-1)*(r-1))/(n-1)) rcorr = r-((r-1)**2)/(n-1) kcorr = k-((k-1)**2)/(n-1) return np.sqrt(phi2corr/min((kcorr-1),(rcorr-1)))
-
1.32.9. Hamming distance - Wikipedia
1.32.10. Kendall tau distance - Wikipedia
1.33. Divergences
1.34. Metric Space vs Topological Space
- To convert a metric space into a topological space tipically you need a decision boundary, which sometimes it’s arbitrary (p > 0.5 or so)
Is there a way to discover the topological numbers that describe your problem and change discontinously like a phase shift in a more natural way other than ROC curves? - Position: Topological Deep Learning is the New Frontier for Relational Learning
- Topological deep learning - Wikipedia
- lrnzgiusti/awesome-topological-deep-learning: A curated list of topological deep learning (TDL) resources and links.
1.35. Entropies
1.35.1. Iciar Martínez - Entropía de Shannon para bancos de peces
Ikerbasque UPV/EHU (Bióloga Marina)
Usa entropía de shannon para medir la actividad de un grupo de peces
https://www.ikerbasque.net/es/iciar-marti-nez
https://www.mdpi.com/1099-4300/20/2/90 → el artículo en cuestión
1.35.2. Entropy coding - Wikipedia
1.35.2.1. Huffman coding - Wikipedia
1.35.2.2. Arithmetic coding - Wikipedia
1.35.2.3. Range coding - Wikipedia
1.36. Alternative languages for data
1.36.2. Rust
1.36.2.1. Are We Learning Yet? - Rust
1.36.2.2. evcxr/evcxr_jupyter at main · google/evcxr → Rust for Data Science?
1.36.3. Relay (TVM) as a backend
Apache TVM is an open source machine learning compiler framework for CPUs, GPUs, and machine learning accelerators. It aims to enable machine learning engineers to optimize and run computations efficiently on any hardware backend.
Language Reference — tvm documentation
1.37. Non-Euclidean Statistics
1.37.2. The geometry of data: the missing metric tensor and the Stein score [Part II] | Terra Incognita
1.37.8.
1.37.9. Maria Alonso-Pena - Google Académico - Circular mean
1.38. Relational Machine Learning
1.39. Machine Learning
1.40. DataForScience/Causality
1.41. Are Observational Studies of Social Contagion Doomed? - YouTube
1.41.1. What We (Should) Agree On
- Social influence exists, is causal, and matters
- Observations of social network don’t, generally, identify influence
- Getting identification will need either special assumptions or richer data
—
- There may be some ways forward
- Richer measurements
- Network clustering (maybe)
- Elaborated mechanisms
- Partial identification
- Richer measurements
1.41.2. Social Influence Exists and Matters
Example: Language: We are all speaking the same language because of social influence. Also happens in small scale through local dialects
Also skills, ideologies, religions, stories, laws, …
Not just copying
Consequences of influence depend bery strongly on the network structure
1.41.2.1. Experiment
Binary choice network (black/red color), random initialization. In each step, some node pick another node at random and become the same color
Spontaneous regions form without any deep reason
1.41.3. Homophily Exists and Matters
1.41.3.1. https://en.wikipedia.org/wiki/Network_homophily
Network homophily refers to the theory in network science which states that, based on node attributes, similar nodes may be more likely to attach to each other than dissimilar ones. The hypothesis is linked to the model of preferential attachment and it draws from the phenomenon of homophily in social sciences and much of the scientific analysis of the creation of social ties based on similarity comes from network science
1.41.3.2. https://en.wikipedia.org/wiki/Homophily
Homophily is a concept in sociology describing the tendency of individuals to associate and bond with similar others
1.41.4. Selection vs. Influence, Homophily vs. Contagion
- Selection
- correlation between disconnected nodes, just because you are selecting some nodes with common properties others are correlated
- Influence
- correlaciton between connected nodes
1.41.5. How Do We Identify Causal Effects from Observations?
1.41.5.1. Confounding - Wikipedia
1.41.5.2. Controls
- Controlling for a variable - Wikipedia
- Control for variables that block all indirect pathways linking cause to effect
- Don’t open indirect paths
- Don’t block direct paths (“back-door criterion”)
1.41.5.3. Instruments
Find independent variation in the cause and trace it throught to the effect
1.41.5.4. Mechanism
Find all the mediating variables linking cause to effect throught direct channels (“front-door criterion”)
1.41.6. Good Control, Bad Control
1.41.8. Endogenous Selection Blas
1.41.9. A Bit More on Lags
1.41.10. A Bit More on Propensity Scores
1.41.11. A Bit More on Asymmetry
1.41.13. OK, What About Instruments?
1.41.15. Summing Up the Negative Part
1.41.16. Richer Measurements
1.41.17. Graph Clustering
1.43. AI Safety
1.45. How to Choose a Feature Selection Method For Machine Learning
1.46. https://en.wikipedia.org/wiki/Mark_d'Inverno
Interesting computer scientist, agent based modelling