MLOps
Table of Contents
- 1. MLOps
- 1.1. Awesome MLOps
- 1.2. Blogs
- 1.3. Why Data is different?
- 1.4. Papers
- 1.5. Data Pipeline
- 1.6. How Fivetran + dbt actually fail Lauren Balik: dataengineering
- 1.6.1. How Fivetran actually fails
- 1.6.2. How dbt — the ‘T’ of ELT — takes rent-seeking to the extreme
- 1.6.3. This is all, of course, rent-seeking gone mad.
- 1.6.4. Trouble with a capital ‘T’
- 1.6.5. Conclusion
- 1.6.6. TICKLER Get Stuff Done with Data - Conference 2022 track
- 1.6.6.1. Snowflake Optimization Power Hour - SELECT
- 1.6.6.2. Alasdair Brown - DataXP
- 1.6.6.3. The Analytics Requirements Document - by Sarah Krasnik
- 1.6.6.4. The Analytics Requirements Document | Sarah Krasnik | Get Stuff Done With Data - YouTube
- 1.6.6.5. Rein in Dashboard Sprawl at Get Stuff Done With Data 2022 - YouTube
- 1.7. Against Config as a Lifestyle. Fight the Trap of Config-Heavy Human Middleware Jobs | by Lauren Balik
- 1.8. ETLs Robustas
- 1.9. A 2020 Reader’s Guide to The Data Warehouse Toolkit
- 1.10. Data Warehouse Concepts: Kimball vs. Inmon Approach | Astera
- 1.11. My (kinda) MLOps Workflow
- 1.12. https://project-haystack.org/ Semantic Data Models
- 1.13. Building Neoway’s ML Platform with a Team-First Approach and Product Thinking | NeowayLabs process
- 1.14. Infrastructure in Go, ML in Python
- 1.15. MLOps / Data Science communities
- 1.16. Buzzwords
- 1.17. Shreya Shankar - MLOps principles I think every ML platform should have
- 1.18. MLOps at a reasonable scale
- 1.18.1. MLOps without Much Ops. Or: How to build AI companies… | by Jacopo Tagliabue | TDS Archive | Medium
- 1.18.2. ML and MLOps at a Reasonable Scale | by Ciro Greco | Towards Data Science
- 1.18.3. Hagakure for MLOps: The Four Pillars of ML at Reasonable Scale | by Ciro Greco | Towards Data Science
- 1.18.4. The modern data pattern. Replyable data processing and ingestion… | by Luca Bigon | Jan, 2022 | Towards Data Science
- 1.18.5. Machine Learning at Reasonable Scale / Jacopo Tagliabue / MLOps Coffee Sessions #66 - YouTube
- 1.19. Full Stack MLOps implementations
- 1.20. MLOps Papers
- 1.21. Problema de Ownership de código
- 1.22. Trustworthy Data for Machine Learning / Chad Sanderson / MLOps Meetup #93 - YouTube
- 1.22.1. Data ownership problem
- 1.22.2. Eventos crudos y eventos semánticos
- 1.22.3. El contrato de datos es bidireccional
- 1.22.4. Evitar ingeniería inversa e histeria de datos
- 1.22.5. Es más sencillo de depurar cosas en streaming que en batch
- 1.22.6. Separación de responsabilidades entre ingenieros y analistas/data scientists
- 1.22.7. Ownership y tensiones entre ingenieros y analistas/data scientists
- 1.22.8. Independencia de base de datos de producción y feature store
- 1.23. Laszlo Sragner | Substack
- 1.24. Tools
- 1.24.1. dbt
- 1.24.2. quantumblacklabs/kedro: A Python framework for creating reproducible, maintainable and modular data science code.
- 1.24.3. ETL Tools
- 1.24.3.1. singer-io/getting-started: This repository is a getting started guide to Singer.
- 1.24.3.2. airbytehq/airbyte: Airbyte is an open-source EL(T) platform that helps you replicate your data in your warehouses, lakes and databases.
- 1.24.3.3. ETL Library for Python process
- 1.24.3.4. Apache AirFlow
- 1.24.3.5. Prefect.io (Premium alternative to AirFlow)
- 1.24.3.6. Bonobo
- 1.24.3.7. pygrametl
- 1.24.3.8. Design and limitations — Luigi stable documentation
- 1.24.4. shilelagh: everything in SQL
- 1.24.5. Differential/Timely Dataflow
- 1.24.6. Tool Compilation
- 1.24.7. DataFlow - Visual flow programming tools - flow-based-programming
- 1.25. Conferences
- 1.26. Lists of Tools
- 1.27. Data Lake / Data Warehouse
- 1.27.1. IBM Architecture of Big Data Solution
- 1.27.2. Data Lake Development with Big Data
- 1.27.3. How to Use the BEAM Approach in Data Analytic Projects | by Christianlauer | Towards Data Science
- 1.27.4. Star schema - Wikipedia
- 1.27.5. Snowflake schema - Wikipedia
- 1.27.6. Dimensional modeling - Wikipedia
- 1.28. reproducibility
- 1.29. Learning MLOps (Gradually) for Free Through Blog Posts & Podcasts
- 1.30. HazyResearch/data-centric-ai: Resources for Data Centric AI
- 1.31. MLOps Is a Mess But That’s to be Expected - MLOps Community
- 1.32. AIIA
1. MLOps
Today’s Data Engineering is Tomorrow’s Quality and Efficiency of Predictive Models
Data Management is about what you’re not to keep a record of (historical data), what you’re going to discard one and for all because is too expensive
MLOps is what happens when DevOps says “I won’t deploy your jupyter notebook”
1.1. Awesome MLOps
1.2. Blogs
1.3. Why Data is different?
https://datacadamia.com/data/warehouse/start
The structure of a data warehouse is very different from that of an operational system:
- Data is not only current and atomic, but also historical and summarised
- Data is organised by subject area such as customer or product, not by business transaction
- Each transaction accesses many data records (batch/bulk process), not one record at a time
- Data is static until refreshed, not dynamic
A data warehouse supports on-line analytical processing (OLAP), as against the on-line transaction processing (OLTP) supported by the operational systems.
Zayd’s Blog – Why is machine learning ’hard’?
When you add data and ML into the mix, they are two more dimensions, often obscure, of failure
- Standard software engineering:
- Bugs in Implementation
- Algorithmic correctness
- Bugs in Implementation
- Add to this in ML:
- Model
- Data
- Model
1.4. Papers
1.6. How Fivetran + dbt actually fail Lauren Balik: dataengineering
Ultimately, ELT is way more heavily rent-seeking than ETL, especially the Fivetran + dbt combination.
- ELT was able to spread during the bull market run/low interest rate boom of the last two years.
- However, as markets compress and the cost of capital increases, many companies simply can’t afford the ELT and will shift back to more ETL — essentially, more data management and schema management and potentially even processing data before the lake/warehouse, not just in it
1.6.1. How Fivetran actually fails
Fivetran was historically priced based on the # of connectors one brought into the data warehouse.
Fivetran then adopted a ‘Monthly Active Row’ model, now offering a highly normalized set of tables derived from its connectors, essentially double, triple, and quadruple billing its customers for every single activity.
But the problem here is there is little inherent value derived from Fivetran’s landed tables — you are going to have to roll them up and inevitably do some amount of denormalization to use this for BI and reporting. Additionally, if you have multiple entities spread across several systems, you will have to resolve these entities in the warehouse as well. An example would be orders and order lines.
If you have order lines spread across multiple systems — like Shopify and say Braintree for a separate sales channel, now you will also bring in Braintree via Fivetran.
Now you have to resolve the entities based on your business logic, in SQL.
Also, now you’re doing finance in the cloud data warehouse.
Also, now you’re probably using dbt to manage the SQL joins, and you’re joining all the time, making railroads in the sky. You’re paying someone a salary to make the railroads in the sky and you’re accruing costs on one of the most expensive compute cycles possible every time this is run.
1.6.1.1. Also, there is no such thing as ELT.
There is a ‘T’ before the L in the ELT — the decision by the EL provider to create as highly normalized as possible landing tables.
This is beneficial to them because when priced on Monthly Active Rows it means more rows are filled, hence more revenue, and it creates more cloud credit attribution which can be used for increases in valuation.
1.6.2. How dbt — the ‘T’ of ELT — takes rent-seeking to the extreme
The distribution has turned into a social media-led full-on get-rich-quick multilevel marketing scheme not unlike most other cults.
This is how the economics of the cloud work — the more people who don’t know what they are doing or are making tech debt on the cloud, the more money the cloud extracts.
Just by getting as many human beings as possible using dbt as much as possible, dbt is more valuable to the cloud as more compute is generated, and thus they can use this to increase their valuation and get more money to keep the party going.
1.6.3. This is all, of course, rent-seeking gone mad.
Data individual contributors seek rent. They want a bump in pay of $10k-$20k or so by adding ‘engineer’ to their ‘analyst’ title, then they use the pre-selected tools that were named for them.
Data teams seek rent. They want workflows offloaded to the cloud data warehouse in their jurisdiction, away from other operational teams. They want power.
Data team leaders seek rent. They want these workflows and they want to hire more employees underneath them to trade for compensation and/or title.
EL vendors seek rent. They are motivated to highly normalize the amount of landing tables for both revenue and cloud credit attribution.
dbt as the ‘T’ vendor seeks rent. When paired with an EL vendor, right off the bat dbt is used to roll back up at least some of the complexity caused by the fixed normalization structure.
Ultimately, this is all just the shuffling around of workflows and money, within individual companies and broadly across the market in aggregate.
1.6.4. Trouble with a capital ‘T’
‘T’ is not at all nuanced and refers to many different things, from joins to unions, to entity resolution, to aggregations, to applying functions, to ‘cleaning’ the data, to shaping it for use with business logic.
In reality there are only two major steps needed here: entity resolution and business logic.
The further you get away from these, the more issues accrue. You start patching fixes to ‘clean’ the data in SQL instead of enforcing contracts and charging back upstream suppliers. You start writing new SQL dependent on the previous SQL dependent on the previous SQL, and so on.
1.6.5. Conclusion
You don’t need all that much dbt.
You can do a little bit of dbt, but not too much.
You don’t need all that much of Reverse ETL and everything else.
You just need to simply get work done and keep things simple and you don’t need data teams sized in the dozens of people.
1.6.6. TICKLER Get Stuff Done with Data - Conference 2022 track
Are they published yet?
1.6.6.2. Alasdair Brown - DataXP
1.7. Against Config as a Lifestyle. Fight the Trap of Config-Heavy Human Middleware Jobs | by Lauren Balik
Config as a Lifestyle breaks down to the deliberate decision to remove oneself from the outcomes of an organization and lock oneself into increasingly nuanced systems integration that is further and further from a positive P&L outcome or net profitability or a revenue center or reality itself.
Marginal employees are hired to solve increasingly marginal problems with an increasing set of point solutions that solve marginal problems.
- The Fallacy of ‘Above the API’ vs. ‘Below the API’ Jobs
‘Above’ jobs are manned by humans who create software and ‘Below’ jobs are manned by humans who are told what to do by the software.
Example: Uber has human engineers building applications (‘Above’) to tell human drivers where to go and what to do (‘Below’), essentially automating away the middle management job of a taxi dispatcher
most of these ‘Above’ jobs are not actually above the application at all. In fact, many of these software and data jobs are within the APIs or among the APIs or around the APIs because the software layer has gotten so thick with so many moving parts. - Startups release half-baked software to collect VC money and externalize development and QA to the community (‘community-driven’ integrations, forums, etc), also bugs and risk
Many CFOs would pull their hair out if they knew how much they were subsidizing these external vendors by employing human middleware that spends more time among the APIs than above them. - Human Middleware Going Forward
In many organizations there are too many people involved in the assembly line. There is too much human middleware on the cloud.
1.8. ETLs Robustas
1.9. A 2020 Reader’s Guide to The Data Warehouse Toolkit
The Data Warehouse Toolkit is that it is organised in terms of use cases, not ideas. What this means is that the first substantive chapter in the book is about retail sales, the next one about inventory, the next on procurement, and so on, each chapter examining a new business activity, and introducing one or more new data modeling ideas within the context of the business problem to be solved.
In their third edition, published in 2013, they added a new chapter (Chapter 2, “Kimball Dimensional Modeling Techniques Overview”), which served as an index for all the ideas that were spread all throughout the text. This chapter is why you should read the third edition, and the third edition only. Use Chapter 2 as a guide to the rest of the book. Jump around to familiarise yourself with Kimball’s techniques. And only read a chapter from beginning to end if it is a business domain you care about.
When Using the Chapter 2 Index, Focus on Timeless Techniques
1.11. My (kinda) MLOps Workflow
1.11.1. Seamsless scaling
Tools that allow the same code to be used both locally and in production
1.11.1.1. Plotly → runs both in jupyter notebooks and in a web server, and can be used to make a presentation
1.11.1.2. Metaflow → runs both locally and in a kubernetes
1.11.2. Model naming convention
<model_name>_%Y-%m-%d_aditional_parameters_zero_padded.joblib
- Sorted alphabetically by date and model parameters (zero padded)
1.11.3. Python vs Java
A lot of the tools built in the ~2010s use Java, which may be a problem if your team doesn’t speak it
A python stack can be built with ray + pandas out-of-core libraries + FastAPI
1.11.4. Early setup
- Lambda/Cloud Function / Container template
With access to all relevant databases, so that you can easily create a new ETL, and email credentials so you can easily create and send a new email
Sending reports by email allows you to get business people off your back, and anyways 95% of all email reports aren’t ever read
Be careful with constraints on serverless deployments as sometimes your job cannot take more than a couple of minutes - Web dashboard to iterate quickly
IT-Sanctioned user management so that people can access it easily, and is easy to add role management in the future
Also import/export interfaces to excel/csv, and cloud storage to create, save, and retrieve files
1.11.5. New data tools
Rust/Arrow is on good track.
Polars based workflow is great since it borrows from PySpark dataframe syntax. And Rust/Arrow combination is a killer.
Datafusion/Ballista are interesting, and if it works well with GPU, it’d be amazing.
DuckDB if you want to plug fast into some SQL analytics.
1.11.6. ETLs Robustas
1.11.8. Notebook centric ML Workflow
1.12. https://project-haystack.org/ Semantic Data Models
We standardize semantic data models and web services with the goal of making it easier to unlock value from the vast quantity of data being generated
https://www.periscopedashboard.com/ uses this model
1.13. Building Neoway’s ML Platform with a Team-First Approach and Product Thinking | NeowayLabs process
A manual for creating a healthy MLOps team
Team topologies applied to MLOps
1.14. Infrastructure in Go, ML in Python
Also there is Python in Dev and Java in Prod for ML
https://github.com/cortexlabs/cortex
- Concurrency is crucial for machine learning infrastructure
- Building a cross-platform CLI is easier in Go
- The Go ecosystem is great for infrastructure projects
ML libraries are written in Python, which means that interfacing with the models — as well as pre and post inference processing — are done in Python.
However, that Python code is packaged up into Docker containers, which are orchestrated by code that is written in Go.
1.15. MLOps / Data Science communities
1.15.1. Eight Data Science Slack Communities to Join in 2021 – DataTalks.Club
https://datatalks.club/blog/slack-communities.html
I’ve joined MLOps.community and the podcast alone is great
1.15.2.
1.15.3. List of Data & Analytics Online Communities | by Maggie @DataStoryteller | Medium
1.16. Buzzwords
1.16.1. A Love Letter to ETL Tools
1.16.1.1. Transactional database are row-oriented, but ETLs are column-oriented
When you do analytics in a transactional (OLTP) database, life is full of tradeoffs. They’re great at acting on individual rows extremely quickly, but for large query loads like those required for reporting, row-based databases like MySQL are sloooow.
…
Among other differences, cloud data warehouses are columnar, meaning they store + query each column separately.
That means if you only select 2 columns from a table, the query will truly only fetch those two columns—as opposed to a row-based transactional database, which would first get entire rows, and then lop off all but those two columns.
1.16.1.2. ELT vs ETL
tldr; ELT is just EtLT
You could call this the ETLT workflow (extract, normalizing transform, load, analytics transform), but most of us just drop the first T and refer to this as the ELT workflow (extract, load, transform).
These naming conventions do not need to be an exact science. What’s important is that there’s a final T at the end of “ELT workflow.” This finality implies freedom—the freedom of analytics teams to transform data to meet the needs of many downstream users (reporting, ML modeling, operational analytics, exploratory analysis, etc).
Without this T living at the end of the workflow, analytics teams are boxed in by the format the data arrives in.
1.16.1.3. What is Reverse ETL: A Definition & Why It’s Taking Off
https://hightouch.io/blog/reverse-etl/
ETL vs Reverse ETL seems like a false dilemma
Reverse ETL is the process of copying data from your central data warehouse to your operational tools, including but not limited to SaaS tools used for growth, marketing, sales, and support.
“I’ve spent all of this money and time getting my data into a warehouse to serve as my single source of truth, and now you’re telling me I need to take my data back out of the warehouse?”
https://hightouch.com/blog/reverse-etl-vs-elt
Without Reverse ETL, your data warehouse is a data silo. All of the data within it is only accessible to your technical users who know how to write SQL. The data only exists in a dashboard or report used to analyze past behavior and not drive future actions. Your business users who are running your day-to-day operations across sales, marketing, support, etc. need access to this data in the tools they use on a daily basis (i.e. Hubspot, Salesforce, Braze, Marketo, Amplitude, etc.).
1.16.2. Wide-column Database
https://www.scylladb.com/glossary/wide-column-database/
NoSQL databases that works well for storing enormous amounts of data that can be collected. Its architecture uses persistent, sparse matrix, multi-dimensional mapping (row-value, column-value, and timestamp) in a tabular format meant for massive scalability (over and above the petabyte scale). Column family stores do not follow the relational model, and they aren’t optimized for joins.
Wide column databases are not the preferred choice for applications with ad-hoc query patterns, high level aggregations and changing database requirements. This type of data store does not keep good data lineage.
1.16.3. Columnar Databases
1.16.4. Data Mesh
https://en.wikipedia.org/wiki/Data_mesh
Data mesh is a sociotechnical approach to build a decentralized data architecture by leveraging a domain-oriented, self-serve design (in a software development perspective), and borrows Eric Evans’ theory of domain-driven design and Manuel Pais’ and Matthew Skelton’s theory of team topologies. Data mesh mainly concerns about the data itself, taking the Data Lake and the pipelines as a secondary concern. The main proposition is scaling analytical data by domain-oriented decentralization. With data mesh, the responsibility for analytical data is shifted from the central data team to the domain teams, supported by a data platform team that provides a domain-agnostic data platform.
https://www.mesh-ai.com/blog-posts/data-mesh-101-federated-data-governance
Data mesh is based on four core principles:
- Domain ownership
- Data as a product
- Self-serve data platform
- Federated computational governance
In addition to these principles, Dehghani writes that the data products created by each domain team should be discoverable, addressable, trustworthy, possess self-describing semantics and syntax, be interoperable, secure, and governed by global standards and access controls. In other words, the data should be treated as a product that is ready to use and reliable.
1.16.5. Model Cards
- An MLOps story: how Wayflyer creates ML model cards
- Google Cloud Model Cards
- Model Cards for Model Reporting
- datasheets.pdf (precursor of Model Cards)
1.17. Shreya Shankar - MLOps principles I think every ML platform should have
https://threadreaderapp.com/thread/1521903041003225088.html
Beginner: use pre-commit hooks. ML code is so, so ugly. Start with the basics — black, isort — then add pydocstyle, mypy, check-ast, eof-fixer, etc.
Beginner: always train models using committed code, even in development. This allows you to attach a git hash to every model. Don’t make ad hoc changes in Jupyter & train a model. Someday someone will want to know what code generated that model…
Beginner: use a monorepo. Besides known software benefits (simplified build & deps), a monorepo reduces provenance & logging overhead (critical for ML). I’ve seen separate codebases for model training, serving, data cleaning, etc & it’s a mess to figure out what’s going on
Beginner: version your training & validation data! Don’t overwrite train.pq or train.csv, because later on, you may want to look at the data a specific model was trained on.
Beginner: put SLAs on data quality. ML pipelines often break because of some data-related bug. There are preliminary tools to automate data quality checks but we can’t solely rely on them. Have an on-call rotation to manually sanity-check the data (eg look at histograms of cols)
Intermediate: put some effort into ML monitoring. Plenty of people are like, “oh we have delayed labels so we don’t monitor accuracy.” Make an on-call rotation for this: manually label a handful of predictions daily, and create a job to update the metric. Some info > no info
Intermediate: retrain models on a cadence (eg monthly) rather than when a KL divergence for an arbitrary feature arbitrarily drops. A cadence is less cognitive overhead. Do some data science to identify a cadence and make sure a human validates the new model every rotation
Advanced: shadow a less-complicated model in production so you can easily serve those predictions with one click if the main model goes down / is broken. ML bugs can take a while to diagnose so it’s good to have a reliable backup
Advanced: put ML-related tests in CI. You can do almost anything in Github Actions. Create test commands that: overfit your training pipeline to a tiny batch of data, verify data shapes, check integrity of features, etc. Whatever your product needs.
1.18. MLOps at a reasonable scale
https://towardsdatascience.com/tagged/mlops-without-much-ops
https://github.com/jacopotagliabue/you-dont-need-a-bigger-boat
1.18.1. MLOps without Much Ops. Or: How to build AI companies… | by Jacopo Tagliabue | TDS Archive | Medium
outside of Big Tech and advanced startups, ML systems are still far from producing the promised ROI: it takes on average 9 months for AI projects to go from pilot to production, and Gartner is betting on year 2024 (!) for enterprises to shift from pilots to operationalization.
how to build and scale ML systems to deliver faster results in the face of the above constraints: small ML teams, limited budget, terabytes of data, limited computing resources
1.18.1.1. invest your time in your core problems and buy everything else.
to be ML productive at reasonable scale you should invest your time in your core problems (whatever that might be) and buy everything else.
Since we are dealing with reasonable scale, there is not much value in devoting resources to deploy and maintain functionalities that today can be found as PaaS/SaaS solutions (e.g. Snowflake, Metaflow, SageMaker).
1.18.1.2. we should do everything in our power to abstract infrastructure away from ML developers
1.18.1.3. ML tools for everyone
yet, the idea of using open source tools is often frowned upon by team leaders and execs
1.18.1.4. Less-is-more
a possibly larger AWS bill is often offset by higher retention rate and greater ML productivity.
1.18.1.5. Empowered developers grow better
recruiting and retention in a competitive market are constant challenges for companies, especially in ML
one of the main reasons for turnover of ML practitioners is devoting a sizable portion of their time to low-impact tasks, such as data preparation and infrastructure maintenance.
1.18.2. ML and MLOps at a Reasonable Scale | by Ciro Greco | Towards Data Science
Most companies are not like Google: they can’t hire all the talent they dream of, they don’t have billions of data points per day and they cannot count on virtually infinite computing power.
Note that the dimensions we are going to introduce are strongly correlated, but there are some exceptions
1.18.2.1. 1. Monetary impact:
ML models at a RS create monetary gains for hundreds of thousands to tens of millions of USD per year (rather than hundreds of millions or billions).
ML in RS companies can have considerable impact, but the absolute scale of such impact rarely reaches the scale of big-data companies.
1.18.2.2. 2. Team size:
RS companies have dozens of engineers (rather than hundreds or thousands).
To optimize for smaller teams, RS companies are often striving to minimize operational friction, that is, to find ways for ML developers and data scientists to rely as little as possible on other teams to get data, provision GPUs, serve models, etc.
much of ML systems’ development depends on the type of problem solved, so data scientists need to be able to make choices about tooling, architecture and modeling depending on datasets, data types, algorithms and security constraints.
In addition, ML systems are not deployed against static environments, so data scientists need to be aware of changes in the data, changes in the model, adversarial attacks, and so on.
At the same time, it is important not to have data scientists involved in too many ancillary tasks, as it would require them to develop too many complementary skills: if it is now their job to provision GPUs, we simply shifted the burden, rather than increasing velocity. Striking the right balance is no mean feat.
1.18.2.3. 3. Data volume:
RS companies deal with terabytes (rather than petabytes or exabytes).
For RS companies, instead, collecting massive training sets is typically not feasible due to issues such as data scarcity, privacy protection, and regulatory compliance or simply mere scale.⁴
Perhaps, excessive focus on top-notch modeling is less than strategically wise. For instance, best in class models might not be optimal in terms of cost/gain ratio or in many cases might not even be a viable option if they are too data hungry.
There is much more marginal gain for RS companies from focusing on clean, standardized and accessible data, as suggested by the original proponents of Data-Centric AI.
1.18.2.4. 4. Computing resources:
RS companies have a finite amount of computing budget.
One of the factors that impacts computational efficiency the most in RS companies is the inefficient design of ML systems from an end-to-end perspective (including the data stack). At RS the focus needs to be equally split between keeping the bill as low as possible and making scaling as efficient as possible.
The paradox is that it is easier for Google to go from 1 GPU to 1000 GPUs than it is to go from 1 GPU to 3 GPU for most RS companies. For instance, plenty of RS companies use distributed computing systems, like Spark, that are unlikely to be required. Much can be achieved with an efficient vertical design that encompasses ways to scale computational resources with minimal effort and only when needed.
1.18.3. Hagakure for MLOps: The Four Pillars of ML at Reasonable Scale | by Ciro Greco | Towards Data Science
The constraints vary wildly between organizations, which makes it difficult to come up with a single recipe for success.
1.18.3.1. 一 Data is superior to modeling
The greater marginal gain for a RS company is always in having clean and accessible data: good data is more important than relative improvements in modeling and model architecture.
- training samples are inherently scarce and iterations cannot be super fast
- data ingestion must include getting data through a standard
you can pick a domain-specific protocol that already exists or come up with your own standard if your data are somewhat unique to your business.
- two events that are meant to describe the very same thing can never have different structures. For every exception to this rule there will be a price to pay sooner than later.
- loose validation and rejection. In general, events should never be rejected, even when they don’t adhere to the standard format agreed upon. The system should flag all ill-formed events, send them down a different path and notify an alert system.
- two events that are meant to describe the very same thing can never have different structures. For every exception to this rule there will be a price to pay sooner than later.
The first consequence of this principle is that data ingestion is a first-class citizen of your MLOps cycle and getting clear data should be the ultimate goal.
1.18.3.2. 二 Log then transform
A clear separation between data ingestion and processing produces reliable and reproducible data pipelines. A data warehouse should contain immutable raw records of each state of the system at any given time.
- the data pipeline should always be built from raw events and implement a sharp separation between streaming and processing.
- The role of the first is to guarantee the presence of truthful snapshots of any given state of the system,
- the latter is the engine to prepare data for its final purpose.
- The role of the first is to guarantee the presence of truthful snapshots of any given state of the system,
The crucial distinction is that the output of the streaming is immutable, while the output of processing can always be undone and modified. The idea here is somewhat counterintuitive if you were raised with the idea that databases are about writing and transforming data, but it really is quite simple at its core: models can always be fixed, data cannot.
- your system allows for replayability?
can you change something in your data transformation, in your queries or in your models and then replay all the data you ingested since the beginning of time without any major problem (time aside)?
If the answer is no, you should really try to change that into a yes, and where not possible, strive to get as close as possible.
1.18.3.3. 三 PaaS & FaaS is preferable to IaaS
Focus is the essence of the RS. Instead of building and managing every component of a ML pipeline, adopt fully-managed services to run the computation.
when resources are limited, it is a good practice to invest them in the most important business problem.
fully-managed services tends to be more expensive in terms of hard COGS (costs), but at the same time data scientists can stop worrying about downtime, replication, auto-scaling and so on.
All those things are necessary, but that does not mean they are central to the purpose of your ML application and
in our experience, the benefits of keeping your organization uniquely focused on the core business problems very often outweigh the benefit of low bills (within reasonable limits)
Because maintaining and scaling infrastructure with dedicated people is still going to be expensive, so in the end it can easily end up being much more costly than paying and managing a handful of new providers.
Moreover, the worst thing about building and maintaining infrastructure is that the actual costs are rather unpredictable over time. Not only is it extremely easy to underestimate the total effort required in the long run, but every time you create a team for the sole purpose of building a piece of infrastructure you introduce the quintessential unpredictability of the human factor.
Consumption bills have very few positive aspects, but one they have for sure is that they can be easily predicted
1.18.3.4. 四 Vertical cuts deeper than distributed
invest your time in your core problems and buy everything else
A RS company does not require distributed computing at every step. Much can be achieved with an efficient vertical design.
- Distributed systems, like Hadoop and Spark, played a pivotal role in the big-data revolution.
Only five years ago Spark was pretty much the only option on the table to do ML at scale.
Startups all around the world use Spark for streaming, SparkSQL for data exploration and MLlib for feature selection and building ML pipelines.
However, they are cumbersome to work with, hard to debug and they also force programming patterns unfamiliar to many scientists, with very negative impacts on the ramp up time of new hires.
The point that we want to make is simple: if you are a RS company, the amount of data you deal with does not require ubiquitous distributed computing: with a good vertical design it is possible to do much of the work while improving significantly the developer experience.
- your ML pipeline should be conceived as a DAG implemented throughout a number of modular steps
while some of them might require more computational firepower, it is important to abstract away the computation piece from the process and the experience of ML development. - Distributed computing should be used for solving vast and intricate data problems.
For everything else, it is more practical to run the steps in the pipeline in separate boxes, scaling up computation in your cloud infrastructure at and only at the steps that require it, like Metaflow allows to do for example. - this shift in perspective has a massive impact on the developer experience of any ML team, because it will give data scientists the feeling of developing locally, without having to go through the hoops and hurdles of dealing with distributed computing all the time.
1.18.3.5. Love thy developer: a corollary about vertical independence
- We want to encourage vertical independence of ML teams.
- Much of the work in ML depends heavily on the type of problem solved, so:
- data scientists need to be able to make reasonably independent choices about tooling, architecture and modeling depending on datasets, data types, algorithms and security constraints.
- ML systems are not deployed against static environments, so
- data scientists need to be aware of changes in the data, changes in the model, adversarial attacks, and so on.
- Much of the work in ML depends heavily on the type of problem solved, so:
- Vertical independence
- vertical independence over embedding into highly compartmentalized organizations
because excessive specialization in this context results in high coordination costs, low iteration rate and difficulties in adapting to environmental changes.
- of all the resources of which RS companies have to budget for, the scarcest one is good engineers.
- makes a great deal of difference when it comes to attract and retain critical talent in RS companies.
- avoid data scientists devoting a sizeable portion of their time to low-impact tasks, such as data preparation, simple analyses, infrastructure maintenance and more generally jumping through the hoops of cumbersome processes.
- it pays off in speed of innovation, minimality, leanness and freedom: the most valuable coin for RS organizations.
- of all the resources of which RS companies have to budget for, the scarcest one is good engineers.
- empower your data scientist
Give your data scientist the possibility to own the entire cycle from fetching the data to testing in production,
make it as easy as possible for them to move back and forth along the different phases of the whole end-to-end pipeline, empower them.
Do it and they will amaze you by developing reliable applications with real business value.
- vertical independence over embedding into highly compartmentalized organizations
1.18.4. The modern data pattern. Replyable data processing and ingestion… | by Luca Bigon | Jan, 2022 | Towards Data Science
We make use of three main technologies:
- Pulumi, which allows us to manage infrastructure-as-code (in Python).
- Snowflake, which allows us to store raw data and manipulate it with powerful queries, abstracting away the complexity of distributed computing.
- dbt, which allows us to define data transformation as versioned, replayable DAGs, and mix-and-match materialization strategies to suit our needs.
1.18.4.1. Version data, not just code
- do not destroy the past forever
- we can’t “time-travel” anymore in our data stack: we can’t debug errors from last week in data-driven system whose input is the catalog — data would have changed by now, and reproducing the state of the system is impossible;
- by losing track of the original state, any update or modification is much harder to undo, in case of mistakes in the business logic;
- it becomes harder to test new code and iterate on it, as different runs will produce slightly different outcomes.
- we can’t “time-travel” anymore in our data stack: we can’t debug errors from last week in data-driven system whose input is the catalog — data would have changed by now, and reproducing the state of the system is impossible;
- append-only log pattern
a never-ending log table and then practical snapshots, capturing the state of the universe at certain points in time
- maintaining a write-only table that stores all data relevant to the universe in which we operate, in one immutable ledger
- since we cannot change the past, our log-like table will be a perpetual memory of the state of our universe at any given point in time.
- From this representation, it is always possible to recover the “previous table” as a view over this stream, that is, a “photograph” capturing for each product the freshest info we have.
- having the freshest table does not destroy previous information, in exactly the same way as running the latest code pulled from git does not destroy previous versions of it
- maintaining a write-only table that stores all data relevant to the universe in which we operate, in one immutable ledger
- This is now way easier to implement than before, as a result of three main trends:
- data storage is getting cheaper by the minute,
- modern data warehouses have superb query performances and great JSON support,
- open source tools like dbt made it easier for people with a broad range of skills to transform data in a versioned, replayable, testable way.
- data storage is getting cheaper by the minute,
1.18.4.2. Building a noOps ingestion platform
The ingestion pipeline mimics a typical data flow for data-driven applications: clients send events, an endpoint collects them and dumps them into a stream, finally a data warehouse stores them for further processing.
In our example, we are providing recommendations for myshop.com, so:
- The clients sending events are the shoppers browsers: as users browse products on myshop.com, a Javascript SDK sends analytics to our endpoint to collect behavioral signals (to be later used for our recommender!). To simulate these on-site events, the repository contains a pumper script, which streams realistic payloads to the cloud;
- the endpoint is responding with a pixel, a 1x1 transparent gif used for dealing with client-server tracking (e.g. Google Analytics);
- behavioral signals are dumped into a raw table in Snowflake;
- SQL-powered transformations (through dbt) take the raw events and build features, intermediate aggregations, normalized views etc. While detailing downstream applications is outside the scope of this post (but see this for a fleshed out example), you can imagine B.I. tools and ML pipelines to use these nicely prepared tables as input to their own workflow.
The endpoint runs in a serverless fashion and will scale automatically thanks to AWS lambda (same goes for data stream on Firehose); Snowflake computing power can be, if necessary, adjusted per query, without any maintenance or arcane configuration (Spark, thinking of you!); the dbt flow can be run either in a SaaS orchestrator (e.g. Prefect) or, even through the “native” dbt cloud.
Once again, our proposal sits in the middle of the spectrum, between the custom infrastructure of tech giants running “impossible scale” loads, and monolithic, end-to-end enterprise platforms, that offer little-to-no-control over the available functionalities.
1.18.4.3. Bonus: re-creating the lambda architecture in one stack
In the Big Data era, lambda architectures were a popular solution for data-driven applications where both historical data — aggregations and counts for the last 30 days — and fresh data — aggregation and counts for the last hour — matter, for visualization, monitoring or ML purposes.
In a nutshell, you run a batch and a streaming system in parallel and join results for clients downstream.
Lambdas faded a bit:
- many critics advocated for leaner solutions not involving maintaining de facto two stacks, and,
- much ML still today doesn’t really use real-time data — and even when it does, it is often the “online prediction with batch features” scenario.
Can we dream again the lambda dream and leverage the modern data stack to get the cake and eat it too?
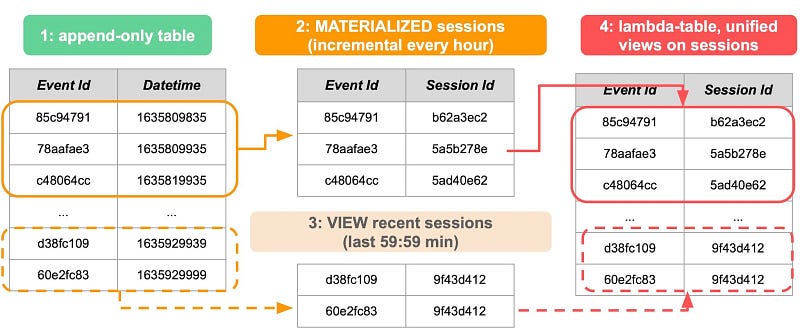
The intuition is that the ever-growing log table (green) can logically be split into two parts: the distant past (orange), immutable and for which sessions have been already assigned, once and for all, and the immediate past (pink), where new events are still coming in and things are still in flux. We can then run the same SQL logic in one stack, avoiding therefore two big drawbacks of original lambda architectures
Barbell strategy applied to distributed systems, means a (false) tradeoff between consistency and availability
While this pattern does not replace a full-fledged low-latency streaming solution, it opens the possibility of doing almost real-time (~5 min) analysis on terabytes of data at a scale and speed that the original lambda architecture, with all its complexity, could only dream of.
If you have already adopted Snowlake, dbt and the log pattern, it also helps you bridge the gap between batch and real-time in a gentle way, before investing in a parallel stack for streaming that you may not need if your acceptable latency is measured in minutes.
1.18.4.4. Lambda architecture
1.20. MLOps Papers
1.21. Problema de Ownership de código
El código de producicón es del data engineer o del data scientist?
1.21.1. Why data scientists shouldn’t need to know Kubernetes
1.21.1.1. Data Scientists Don’t Need to Know Kubernetes with Metaflow - Outerbounds
The first step is to enable data science and machine learning practitioners to use K8s clusters as pools of compute resources. Data science is an inherently compute-heavy activity and we can use K8s as an engine to power it.
Metaflow makes it easy to start by running everything locally but when you need to scale, it allows you to smoothly move parts of your workflows to K8s by adding a single line of code.
«Literally is just using a decorator =@kubernetes=»
1.22. Trustworthy Data for Machine Learning / Chad Sanderson / MLOps Meetup #93 - YouTube
1.22.1. Data ownership problem
Un ingeniero cambia algo no lo dice el equipo de datos y rompe un modelo que está funcionando en producción
Los datos no están versionados porque al equipo de desarrollo de software le vale así y no piensan en los data scientists
1.22.1.1. Histeria de datos e ingeniería inversa
Esto lleva a que se empieza a coger datos de bases de datos que no estaban pensados para ellos y a hacer ingeniería inversa la lógica de negocio
Cuando se rompe algo en producción no se sabe de qué equipo es la culpa
1.22.2. Eventos crudos y eventos semánticos
- Eventos crudos
- actualizaciones de cosas, simplemente cosas que pasan (a una entidad) (por ejemplo, el usuario inicia sesión)
«Realmente el usuario inicia sesión en la web, pero normalmente la web no está modelada en en software ⇒ no es una entidad» - Eventos semánticos
- relaciones entre distintas entidades, productos o eventos, tienen al menos un verbo (por ejemplo, el usuario compra un producto)
1.22.3. El contrato de datos es bidireccional
El ingeniero de datos tiene que dar un servicio de datos con datos de calidad
El científico de datos tiene que aceptar no redefinir varias veces cada cosa, no saltarse los procedimientos para hacer una cosa más rápido, y mantener un cierto estándar de calidad de código, porque entonces pone en peligro la calidad de lo que saca y el trabajo del ingeniero no vale para nada
1.22.4. Evitar ingeniería inversa e histeria de datos
para evitar hacer ingeniería inversa → preguntar a los data scientist como les gustaría tener la base de datos a ellos
Cuando el data scientist quiere implementar un nuevo campo en la base de datos/feature store el proceso de pedirlo a un ingeniero de software y luego que lo valide el data scientist tiene el problema de que:
- los conceptos puede que no sean los mismos entre desarrolladores y data scientists
- va ser por lo general un proceso muy lento
—
- La solución es Automatizar al desarrollador de software
Han montado un sdk que permite conectarse a un sistema de topics/mensajes pub/sub estilo Kafka utilizando python/sql (lenguaje del data scientist) para procesar todos los datos y transformarlos con funciones de ventana o lo que necesiten
1.22.5. Es más sencillo de depurar cosas en streaming que en batch
porque las cosas en batch tardan en ejecutarse y el feedback es más lento
1.22.6. Separación de responsabilidades entre ingenieros y analistas/data scientists
el equipo de ingeniería de datos se ocupa de la infraestructura y los equipos de analítica y data science se ocupan de la calidad de los datos que crean
1.22.7. Ownership y tensiones entre ingenieros y analistas/data scientists
El equipo de ingeniería no se quiere ocupar de la lógica de negocio porque no la entiende, y el equipo de data science no quiere ocuparse de la calidad del código porque no tienen esa formación
El data scientist no tiene que ocuparse de la calidad del código, pero de nuevo es algo que va en ambas partes
Aportar valor al negocio tan rápido como sea posible y la calidad del código siempre van a estar en conflicto porque no son lo mismo
1.22.8. Independencia de base de datos de producción y feature store
una ventaja para los ingenieros de software es que no tienen que preocuparse de que el equipo de data science añada dependencias a detalles de implementación de lo que están programando
Así el equipo de ingenieros de software pueden cambiar el código sin romper un modelo que está en producción
1.23. Laszlo Sragner | Substack
1.23.2. Data Science code quality hierarchy of needs
most people have a “completionist” view of code quality. They treat the topic as an all-or-nothing exercise where achieving “production code” is a checkboxing exercise (have typing? check. have docstrings? check. have unittests? check).
This makes investing in the DS codebase an expensive exercise which requires higher level “business value” arguments. As a checkboxing exercise, the benefits are not clear and hard to assess its ROI. Let’s be honest; most advice indeed does not sound useful or beneficial at all.
1.23.2.1. When does this apply: Analysis vs Creation
ML Data Scientists operate in two primary mindsets: Analysis and Creation.
- Analysis is:
- improving their understanding of the context (business, environment, data, product).
- updating their mental model of the world (queries, stats, diagrams).
- shortlived and dynamic, emphasis is on speed.
- improving their understanding of the context (business, environment, data, product).
- Creation is
- actively influencing the world through building ML products (code, data transformations, datasets, models). Of course, next, they switch back to analysis mode to understand if they are influencing in the right way.
- long-term, iterated, emphasising agility (ability to respond to change).
- actively influencing the world through building ML products (code, data transformations, datasets, models). Of course, next, they switch back to analysis mode to understand if they are influencing in the right way.
1.23.2.2. SWE is highly specified and instant, while ML is only statistically correct.
SWE: if something is wrong and breaks specs, you can immediately know
ML: You can only validate your work over a longer term.
1.23.2.3. Hierarchy of Needs
- Version Control
It turns overwriting your codebase from “high risk, can’t recover” into “you mess up something you can backtrack”
- Functional testing
Software engineers have unit testing, but does it work in ML?
If you know that your code produces the right results, save it, change your code, rerun it and compare it to the saved version. Boom, functional testing. If it doesn’t change, you probably didn’t break anything.
Too slow? Save and run it only on a sample (0.1%-1%), compare only that and only occasionally run more extensive tests (10%-100%) of the dataset.
- Comments, documentation «this should be way higher, maybe 2nd»
«No difference between code documentation and model documentation»
1.24. Tools
1.24.1. dbt
https://discourse.getdbt.com/t/dbt-cli-vs-dbt-cloud-convince-me/4022
https://about.gitlab.com/handbook/business-technology/data-team/platform/dbt-guide/
1.24.1.1. Viewpoint | dbt Docs process
The last two points are mostly copy paste
- Common Tools are shifting from proprietary, end-to-end tools to composable, open-source pipelines
- data integration scripts and/or tools,
- high-performance analytic databases,
- SQL, R, and/or Python, and
- visualization tools.
- data integration scripts and/or tools,
- analytics teams have a workflow problem
- analysts operate in isolation
- Knowledge is siloed, analysis are rewritten unecessarily
- We fail to grasp the nuances of unfamiliar datasets
- calculations of a shared metric differ
- analysts operate in isolation
- Analytics is collaborative
So we need the following features:
- Version Control
Since it’s important to know who changed what, when, and to be able to work seamlessly in parallel - Quality Assurance
Since bad data can lead to bad analyses, and bad analyses can lead to bad decisions - Documentation
Since people are going to have questions about how to use it and need exact definitions of metrics - Modularity
Analysis sharing a metric should use the same input data
Copy-paste is not a good approach here – if the underlying definition changes, it will need to be updated everywhere it was used
think of the schema of a data set as its public interface
- Version Control
- Analytic code is an asset
So wee need a way to protect and grow it
- Environments
Analysts need the freedom to work without impacting users, while users need service level guarantees so that they can trust the data - Service level guarantees
Analytics teams should stand behind the accuracy of all analysis that has been promoted to production.
Errors should be treated with the same level of urgency as bugs in a production product.
Any code being retired from production should go through a deprecation process. - Design for maintainability
Most of the cost involved in software development is in the maintenance phase. Because of this, software engineers write code with an eye towards maintainability. Analytic code, however, is often fragile. Changes in underlying data break most analytic code in ways that are hard to predict and to fix.
Analytic code should be written with an eye towards maintainability. Future changes to the schema and data should be anticipated and code should be written to minimize the corresponding impact.
- Environments
- Analytics workflow is often manual and time-consuming
So we need tools similar to that of software engineeres are required. Here’s one example of an automated workflow:
- models and analysis are downloaded from multiple source control repositories,
- code is configured for the given environment,
- code is tested, and
- code is deployed.
Workflows like this should be built to execute with a single command.
- models and analysis are downloaded from multiple source control repositories,
1.24.1.2. Stefano Solimito Medium Series
- Practical tips to get the best out of Data Build Tool (dbt) — Part 1 | by Stefano Solimito | Unboxing Photobox | Medium
- Practical tips to get the best out of Data Build Tool (dbt) — Part 2 | by Stefano Solimito | Unboxing Photobox | Medium
- Practical tips to get the best out of Data Build Tool (dbt) — Part 3 | by Stefano Solimito | Unboxing Photobox | Medium
- Photobox New Data Platform. Building a self-service even driven… | by Stefano Solimito | Unboxing Photobox | Feb, 2022 | Medium
1.24.1.3. My Guide
pip install dbt-postgres
mkdir dbt_test && cd dbt_test
dbt init
- config is stored in ~/.dbt/profiles.yml, with one configuration per environment, edit it
dbt debug # test connection dbt run # run models
dbt seedallows you to copy csvsdbt compileto get the actual sql migrations
—
dbt models
A model is aselectstatement. Models are defined in.sqlfiles (typically in yourmodelsdirectory):
- Each
.sqlfile contains one model /selectstatement - The name of the file is used as the model name
- Models can be nested in subdirectories within the
modelsdirectory
When you execute the
dbt runcommand, dbt will build this model in your data warehouse by wrapping it in acreate view asorcreate table asstatement.
- https://www.startdataengineering.com/post/dbt-data-build-tool-tutorial/
- can depend on other models
- have tests defined on them (schema test and data test)
- can be created as tables or views (materializations, which are strategies for persisting dbt models in a warehouse)
- can depend on other models
- Each
- jinja & macros
Using Jinja turns your dbt project into a programming environment for SQL, giving you the ability to do things that aren’t normally possible in SQL. For example, with Jinja you can: - Use control structures (e.g.
ifstatements andforloops) in SQL - Use environment variables in your dbt project for production deployments
- Change the way your project builds based on the current target.
- Operate on the results of one query to generate another query, for example:
- Return a list of payment methods, in order to create a subtotal column per payment method (pivot)
- Return a list of columns in two relations, and select them in the same order to make it easier to union them together
- Return a list of payment methods, in order to create a subtotal column per payment method (pivot)
- Abstract snippets of SQL into reusable macros — these are analogous to functions in most programming languages.
1.24.1.4. The Spiritual Alignment of dbt + Airflow | dbt Developer Blog process
The “Airflow + Dbt examples” is mostly unprocessed
they both provide common interfaces that data teams can use to get on the same page.
- Airflow provides common interface to logging storage, view, monitoring, and rerunning failed jobs (overall pipeline health and management) → pipeline orchestation
- dbt provides common interface to boilerplate DDL, dependency management between scripts, … → data transformation layer
- Skills Required

The common skills needed for implementing any flavor of dbt (Core or Cloud) are:
- SQL: non-negotiable you’ll need to work. SQL skills are shared by data people + engineers ⇒ SQL-based transformations (as in dbt) are a common interface.
- YAML: can be learned pretty quickly, required to generate config files for writing tests on data models
- Jinja: can be learned pretty quickly, allows you to write DRY code (using macros, for loops, if statements, etc)
To layer on Airflow, you’ll need more software or infrastructure engineering-y skills to build + deploy your pipelines:
- Python
- Docker
- Bash (for using the Airflow CLI)
- Kubernetes
- Terraform
- secrets management
- SQL: non-negotiable you’ll need to work. SQL skills are shared by data people + engineers ⇒ SQL-based transformations (as in dbt) are a common interface.
- Airflow + Dbt examples
- Pipeline observability for analysts
If your team’s dbt users are analysts rather than engineers, they still may need to be able to dig into the root cause of a failing pipeline
analysts can pop open the Airflow UI to monitor for issues, rather than opening a ticket or bugging an engineer in Slack
- Transformation observability for engineers
When a dbt run fails within an Airflow pipeline, an engineer monitoring the overall pipeline will likely not have the business context to understand why the individual model or test failed—they were probably not the one who built it.
dbt provides common programmatic interfaces that provide the context needed for the engineer to self-serve—either by rerunning from a point of failure or reaching out to the owner.
- Pipeline observability for analysts
1.24.1.5. Why does dbt have so much hype/ metions in this subreddit?
https://www.reddit.com/r/dataengineering/comments/ve2qbp/why_does_dbt_have_so_much_hype_metions_in_this/
Useful for people without software engineering to write clean code, easy to learn
- The use of Jinja macros with SQL
- The ability to see lineage
- The ability to automate the generation of docs for your users
- That you don’t need to worry about the order of table updates
- That you can very simply add tests to your code in a standard and repeatable fashion.
1.24.2. quantumblacklabs/kedro: A Python framework for creating reproducible, maintainable and modular data science code.
Kedro is built upon our collective best-practice (and mistakes) trying to deliver real-world ML applications that have vast amounts of raw unvetted data. We developed Kedro to achieve the following:
- To address the main shortcomings of Jupyter notebooks, one-off scripts, and glue-code because there is a focus on creating maintainable data science code
- To enhance team collaboration when different team members have varied exposure to software engineering concepts
- To increase efficiency, because applied concepts like modularity and separation of concerns inspire the creation of reusable analytics code
- Has good DataFrame integrations, but setup with databases is a complicated setup since you need to connect to them using ; furthermore you need a plugin to connect kedro with dolt
- Kedro has an emphasis on experiment tracking, for example it doesn’t manage migrations like dbt
https://blog.developer.bazaarvoice.com/2020/11/16/kedro-6-months-in/
By using Kedro in the experimentation phase of projects, I can build maintainable and reproducible data pipelines that produce consistent experimental results.
https://github.com/kedro-org/kedro/issues/360
If you’re stuck in a SQL world it dbt is the best thing I’ve seen there, but in the PySpark/Python world Kedro could be a good fit for what you’re trying to do.
- https://kedro.readthedocs.io/en/stable/kedro.extras.datasets.html
1.24.3. ETL Tools
1.24.3.3. ETL Library for Python process
https://www.reddit.com/r/Python/comments/pwq8q7/etl_library_for_python/
pandas is good.
pyjanitor can extend pandas and help you write clean code to clean data.
dask can help pandas scale.
prefect can orchestrate.
airflow can also orchestrate.
pyspark scales but uses spark under th hood.
koalas is like pandas, but spark under the hood.
great_expectations can test and document data.
pandera can statistically test data.
1.24.3.4. Apache AirFlow
Also does orchestration
1.24.3.5. Prefect.io (Premium alternative to AirFlow)
1.24.3.6. Bonobo
1.24.3.7. pygrametl
1.24.4. shilelagh: everything in SQL
1.24.5. Differential/Timely Dataflow
1.24.6. Tool Compilation
1.24.6.1. Red Hot: The 2021 Machine Learning, AI and Data (MAD) Landscape – Matt Turck process
1.24.6.2. DataEngineering 2021 in one pic : dataengineering
1.24.6.3. The State of Data Engineering 2022
1.24.7. DataFlow - Visual flow programming tools - flow-based-programming
1.25. Conferences
1.25.1. mlcon
1.25.1.1. mlcon 2.0 - The AI and ML Developer Conference | By cnvrg.io
1.25.1.2. https://cnvrg.io/mlcon-2021/
1.25.2. apply() Conference - The ML data engineering conference series
1.26. Lists of Tools
1.26.1. MLOps Model Stores: Definition, Functionality, Tools Review - neptune.ai
1.27. Data Lake / Data Warehouse
Arquitectura tradicional de estas cosas. Parece que basado en esto:
Agile Data Warehouse Design: Collaborative Dimensional Modeling, from Whiteboard to Star Schema
1.27.1. IBM Architecture of Big Data Solution
1.27.2. Data Lake Development with Big Data
1.27.3. How to Use the BEAM Approach in Data Analytic Projects | by Christianlauer | Towards Data Science
1.27.3.1. Principles
The key principles of this concept are:
- Individuals and Interactions: Business intelligence is driven by what users ask about their business. The technical setting is secondary.
- Business Driven: Well documented data warehouses that take years to deploy will always be out of date. Business users will look elsewhere. My experiences with business units: I need it now or I’d rather stick with Excel solution ….
- Customer Collaboration: End users’ knowledge of their business is your greatest resource.
- Responding to Change: If you take all of the above actions, change will come naturally and result in weekly delivery cycles.
1.27.4. Star schema - Wikipedia
1.27.5. Snowflake schema - Wikipedia
1.27.6. Dimensional modeling - Wikipedia
1.28. reproducibility
1.30. HazyResearch/data-centric-ai: Resources for Data Centric AI
https://github.com/hazyresearch/data-centric-ai
We’re collecting (an admittedly opinionated) list of resources and progress made in data-centric AI, with exciting directions past, present and future. This blog talks about our journey to data-centric AI and we articulate why we’re excited about data as a viewpoint for AI in this blog.
While AI has been pretty focused on models, the real-world experience of those who put models into production is that the data often matters more. The goal of this repository is to consolidate this experience in a single place that can be accessed by anyone who wants to understand and contribute to this area.
1.31. MLOps Is a Mess But That’s to be Expected - MLOps Community
1.32. AIIA
Canonical Stack → Use the big models created by big tech (?)
- WEBINAR: The Canonical MLOps Stack | Pachyderm
- Why We Started the AIIA and What It Means for the Rapid Evolution of the Canonical Stack of Machine Learning - AI Infrastructure Alliance
- Rise of the Canonical Stack in Machine Learning | by Daniel Jeffries | Towards Data Science
- The Rapid Evolution of the Canonical Stack for Machine Learning | by ODSC - Open Data Science | Medium