distributed systems
Table of Contents
- 1. distributed systems
- 1.1. Resources
- 1.2. Lamport timestamp
- 1.3. Vector clock
- 1.4. Version vector
- 1.5. Interval Tree Clocks
- 1.6. Inconsistency is concurrent mutation in a time window without communication
- 1.7. Distributed Systems and Relativity
- 1.8. Syncthing
- 1.9. Mirarse el paper de Duplicacy (Lock Free Deduplication) read
- 1.10. A Complete Guide to UUID Versions (v1, v4, v5) - With Examples
- 1.11. Joe Armstrong → Creador de Erlang
- 1.12. CAP theorem
- 1.12.1. https://web.archive.org/web/20250905071809/https://codahale.com/you-cant-sacrifice-partition-tolerance/
- 1.12.2. PACELC theorem
- 1.12.3. CAP and PACELC: Thinking More Clearly About Consistency - Marc’s Blog
- 1.12.4. Optimism vs Pessimism in Distributed Systems - Marc’s Blog
- 1.12.5. “A Critique of the CAP Theorem”
- 1.12.6. Patterns of Distributed Systems
- 1.12.7. Consistency model
- 1.12.8. Distributed Database - CAP Theorem | Distributed | Datacadamia - Data and Co
- 1.12.9. How to beat the CAP theorem - thoughts from the red planet process
- 1.13. Distributed Systems Shibboleths | Joey Lynch’s Site
- 1.14. CRDT Conflict-free replicated data type
- 1.14.1. The CRDT Dictionary: A Field Guide to Conflict-Free Replicated Data Types - Ian Duncan - Ian Duncan
- 1.14.2. A Run of CRDT Posts | Async Stream
- 1.14.3. alangibson/awesome-crdt: A collection of awesome CRDT resources
- 1.14.4. [2004.00107] Merkle-CRDTs: Merkle-DAGs meet CRDTs
- 1.14.5. Used in Interoperable Distributed Components
- 1.14.6. Replicated Data Types as composable types
- 1.14.7. Tree CRDT
- 1.14.8. An Interactive Intro to CRDTs | jakelazaroff.com
- 1.14.9. CRDTs Turned Inside Out
- 1.14.10. Introduction to Loro’s Rich Text CRDT – Loro
- 1.14.11. ljwagerfield/crdt: CRDT Tutorial for Beginners (a digestible explanation with less math!)
- 1.14.12. Code • Conflict-free Replicated Data Types
- 1.14.13. You might not need a CRDT | Hacker News
- 1.14.14. Code • Conflict-free Replicated Data Types
- 1.14.15. CRDTs Turned Inside Out
- 1.14.16. Lies I was told about collab editing, Part 1: Algorithms for offline editing | Hacker News
- 1.14.17. Grove: A Bidirectionally Typed Collaborative Structure Editor Calculus
- 1.14.18. About CRDTs • Conflict-free Replicated Data Types
- 1.15. Software Transactional Memory
- 1.16. rpwiki - Relativistic Programming
- 1.17. Wishlist: Reduction-Based Scheduling (Erlang)
- 1.18. Leslie Lamport - A Science of Concurrent Programs
- 1.19. Non-lock concurrency
- 1.20. Classical concurrency problems
- 1.21. https://en.wikipedia.org/wiki/Paxos_(computer_science)
1. distributed systems
1.1. Resources

1.2. Lamport timestamp
https://en.wikipedia.org/wiki/Lamport_timestamp
A→B (A happened before B), C(A) is the Lamport Clock value of A
Generates a partially ordered set (poset). Ordering is:
- Reflexive (each element is comparable to itself)
- Antisymmetric (no two different elements precede each other)
- Transitive (A→B and B→C ⇒ A→C)
Example: genealogical descendency. Some pairs are incomparable, with neither being a descendent of the other
1.2.1. Rules
- A process increments its counter before each event in that process
- When a process sends a message, it includes the counter value
- On receiving a message, the counter of the recipient is updated, if necessary, to the greater of its current counter and the received counter
The counter is then incremented by 1 before the message is considered received
1.2.2. Considerations
There is a minimum of one clock tick between any two events
It might be necessary to attach a Process ID to uniquely identify each message
1.2.3. Implications
a→b ⇒ C(a) < C(b) but C(a) < C(b) ⇒ a→b can only be achieved:
- Other techniques (vector clock)
- Total ordering of events by using an arbitrary mechanism to break ties (e.g. the Process ID)
1.3. Vector clock
https://en.wikipedia.org/wiki/Vector_clock
- Each time a process experiences an internal event, it increments its logical clock by one
- Each time a process sends a message, it increments its own logical clock by one (as in 1., but not twice for the same event) and then sends a copy of its own vector
(transmmits would be more accurate, the message “goes through”) - Each time a process receives a message, it increments its own logical clock by one and updates each element in its vector by taking clock by one and updates each element in its vector by taking max(own[i], received[i]) for each element in the vector
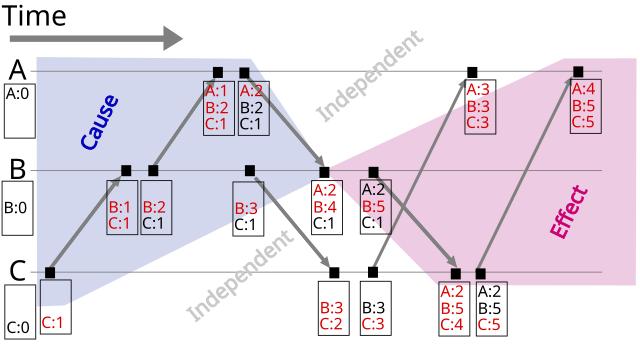
1.3.1. Vector Clocks: Keeping time in check – Distributed Computing Musings
1.4. Version vector
https://en.wikipedia.org/wiki/Version_vector
Replicas can either experience local updates or sync with another replica
- Each time a replica experiences a local update event, it increments its own counter by one
Each time a replica a and b sync, the both set the elements to the maximum of the element across both counters (identical vectors after sync)
V_a[x] = V_b[x] = max(V_a[x], V_b[x])
- Replicas can be compared
- Identical a == b
- Ordered a <= b, b>=a for all elements and strict inequality for at least one element
- Concurrent a || b, none of the above
- Identical a == b
1.5. Interval Tree Clocks
1.6. Inconsistency is concurrent mutation in a time window without communication
Concurrent mutation of a given value in the same value in a time window in which there is no communication generates desynchronization (events are cannot be ordered using Lamport timestamps )
1.7. Distributed Systems and Relativity
1.7.1. Lagrangian vs Hamiltonian
1.8. Syncthing
1.9. Mirarse el paper de Duplicacy (Lock Free Deduplication) read
1.10. A Complete Guide to UUID Versions (v1, v4, v5) - With Examples
- V1 : Uniqueness
UUID v1 is generated by using a combination the host computers MAC address and the current date and time. In addition to this, it also introduces another random component just to be sure of its uniqueness. - V4 : Randomness
The bits that comprise a UUID v4 are generated randomly and with no inherent logic.
chance that a UUID could be duplicated: possible combinations (2^124) → generating trillions of IDs every second, for many years.
124: 128 bits - 4 bits that are always equal V5: Non-Random UUIDs
UUID v5 is generated by providing two pieces of input information:
- Input string: Any string that can change in your application.
- Namespace: A fixed UUID used in combination with the input string to differentiate between UUIDs generated in different applications, and to prevent rainbow table hacks
These two pieces of information are converted to a UUID using the SHA1 hashing algorithm.
UUID v5 is consistent → given combination of input and namespace will result in the same UUID, every time
- Input string: Any string that can change in your application.
1.11. Joe Armstrong → Creador de Erlang
1.11.1. “Systems that run forever self-heal and scale” by Joe Armstrong (2013) - YouTube
1.11.2. Kubernetes and the Erlang VM: orchestration on the large and the small « Plataformatec Blog
1.11.3. “The Mess We’re In” by Joe Armstrong
1.11.3.1. cjb/GitTorrent: A decentralization of GitHub using BitTorrent and Bitcoin
1.11.3.2. Kademlia - Wikipedia
1.11.3.3. Chord (peer-to-peer) - Wikipedia
1.12. CAP theorem
any distributed data store can only provide two of the following three guarantees:
- Consistency
Every read receives the most recent write or an error. - Availability
Every request receives a (non-error) response, without the guarantee that it contains the most recent write. - Partition tolerance
The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.
When a network partition failure happens, it must be decided whether to
- cancel the operation and thus decrease the availability but ensure consistency or to
- proceed with the operation and thus provide availability but risk inconsistency.
1.12.2. PACELC theorem
It states that in case of network partitioning (P) in a distributed computer system, one has to choose between availability (A) and consistency (C) (as per the CAP theorem), but else (E), even when the system is running normally in the absence of partitions, one has to choose between latency (L) and consistency (C).
All distributed systems come with a tradeoff between consistency and liveness
Any system connected to another system is already distributed, no matter how simple it may seem
1.12.4. Optimism vs Pessimism in Distributed Systems - Marc’s Blog
Most of the CPUs we’re familiar with keep their caches coherent using protocols like MESI. These protocols are interesting, because they allow coordination avoidance for unmodified items, at the cost of tracking state and ownership and assuming that the coherency protocol is correctly executed by all participants.
1.12.5. “A Critique of the CAP Theorem”
the FLP impossibility theorem shows that is it impossible to build a distributed consensus algorithm that will always terminate.
1.12.6. Patterns of Distributed Systems
1.12.7. Consistency model
1.12.8. Distributed Database - CAP Theorem | Distributed | Datacadamia - Data and Co

- For AP (availability over consistency, ie always on), see Database - Nosql and Data Property - BASE (Basically Available)
- For CP (consistency over availability), see NewSQL.
- For AC (ie ACID), the system is on a single node, this is no more a distributed system but a conventional database.
As AC refers to traditional database, the choice is really between consistency versus availability in case of a network partition or failure. When choosing:
- CP, the system will return an error or a time-out if particular information cannot be guaranteed to be up to date due to network partitioning.
- AP, the system will always process the query and try to return the most recent available version of the information, even if it cannot guarantee it is up to date due to network partitioning.
1.12.9. How to beat the CAP theorem - thoughts from the red planet process
Related to the lambda architecture
1.12.9.1. Batch layer + realtime layer, the CAP theorem, and human fault-tolerance
In some ways it seems like we’re back to where we started. Achieving realtime queries required us to use NoSQL databases and incremental algorithms. This means we’re back in the complex world of divergent values, vector clocks, and read-repair.
There’s a key difference though. Since the realtime layer only compensates for the last few hours of data, everything the realtime layer computes is eventually overridden by the batch layer. So if you make a mistake or something goes wrong in the realtime layer, the batch layer will correct it. All that complexity is transient.
This doesn’t mean you shouldn’t care about read-repair or eventual consistency in the realtime layer. You still want the realtime layer to be as consistent as possible. But when you make a mistake you don’t permanently corrupt your data. This removes a huge complexity burden from your shoulders.
In the batch layer, you only have to think about data and functions on that data. The batch layer is really simple to reason about. In the realtime layer, on the other hand, you have to use incremental algorithms and extremely complex NoSQL databases. Isolating all that complexity into the realtime layer makes a huge difference in making robust, reliable systems.
1.13. Distributed Systems Shibboleths | Joey Lynch’s Site
https://jolynch.github.io/posts/distsys_shibboleths/
- Idempotency
Most useful distributed systems involve mutation of state communicated through messages. The only safe way to mutate state in the presence of unreliable networks is to do so in a way that you can apply the same operation multiple times until it explicitly succeeds or fails. - Incremental progress
partitions happen for all kinds of reasons: network delay/failure, lock contention, garbage collection, or your CPU might just stop running code for a bit while it does a microcode update.
The only defense is breaking down your larger problem into smaller incremental problems that you don’t mind having to re-solve in the error case. - Every component is crash-only
I like to think of this one as the programming paradigm which collectively encourages you to “make operations idempotent and make incremental progress” because handling errors by crashing forces you to decompose your programs into small idempotent processors that make incremental progress. - We shard it on <some reasonably high cardinality value>
Distributed systems typically handle large scale datasets. A fundamental aspect of building a distributed system is figuring out how you are going to distribute the data and processing. This technique of limiting responsibility for subsets of data to different sets of computers is the well-known process of sharding. A carefully-thought-out shard key can easily be the difference between a reliable system and a constantly overloaded one. - Our system is Consistent and Available.
Coda Hale presented a compelling argument for this back in 2010 and yet I still hear this somewhat routinely in vendor pitches. What does exist are datastores that take advantage ofPACELCtradeoffs to either provide higher availability toCPsystems such as building fast failover into a leader-follower system (attempting to cap the latency of the failure), or provide stronger consistency guarantees toAPsystems such as paying latency in the local datacenter operations to operate with linearizability while remote datacenters permit stale or phantom reads. - at-least-once and at-most-once are nice, but our system implements exactly-once
No it does not. Your system might implement at-least-once delivery with idempotent processing, but it does not implement exactly-once which is demonstrated to be impossible in the Two Generals problem.
if you actually read what they built it is just idempotent processing of at-least-once delivery - I just need Transactions to solve my distributed systems problems
Transactions can still timeout and fail in a distributed system, in which case you must read from the distributed system to figure out what happened. The main advantage of distributed transactions is that they make distributed systems look less distributed by choosing CP, but that inherently trades off availability! Distributed transactions do not instantly solve your distributed systems problems, they just make a PACELC choice that sacrifices availability under partitions but tries to make the window of unavailability as small as possible.
1.14. CRDT Conflict-free replicated data type
1.14.1. The CRDT Dictionary: A Field Guide to Conflict-Free Replicated Data Types - Ian Duncan - Ian Duncan
1.14.2. A Run of CRDT Posts | Async Stream
- Deep Roots: CRDTs are based on semilattices, which are simple, abstract mathematical structures that have a
joinoperator that is associative, commutative, and idempotent. - Moar Algebra!: The use of modern algebra as a building block for correctness in distributed systems and database systems is a wonderful direction for the field, and we’re seeing more and more of this work in recent years.
Unfortunately there are few key problems that arise in common discussion of CRDTs:
- Drifting from Correctness. As people walk away from the semilattice foundation, they can lose their moorings in correct math.
- Unsafe to Use. The algebra of semilattices has a single operator:
join. Notably it doesn’t have any operator that corresponds to read or inspect. In fact, CRDTs as described in the literature provide absolutely no guarantees to readers, so a “proper” CRDT implementation should not allow reads! Which is to say a correct CRDT is an entirely useless theoretical object. Yet people use CRDTs, inevitably reading/inspecting them in unsafe/non-deterministic ways. Worse, many developers think they’re getting useful correctness guarantees from CRDTs, which they are not! The only safe thing to do with a CRDT is to leave it unexamined. - Programmability Issues. As unreadable data types, CRDTs can’t be composed safely into useful programs. How in fact can we use them? Ideally we’d like a language that allows correct composition of CRDT building blocks. This is something folks have looked at in DSLs like LVars, Bloom^L, Lasp and Gallifrey. There’s still work to do to deliver those ideas to developers in a familiar frame, which is one goal of our Hydro library for Rust.
https://jhellerstein.github.io/blog/crdt-turtles/
A semilattice is:
- A set of states \[\(S\)\]
- A
joinfunction \[\(\left. \sqcup :S \times S\rightarrow S \right.\)\] that must satisfy commutativity, associativity, and idempotence.The
joinfunction induces a partial order: \[\(\left. x \leq y\text{\:\,}\Longleftrightarrow\text{\:\,}x \sqcup y = y \right.\).\]
CRDTs sometimes add additional “update” operators:
update\[\(\left. :U\rightarrow(S\rightarrow S) \right.\)\]
updatetakes an input value of type \[\(U\)\] and uses it to directly mutate the local CRDT’s state.
When discussing CRDTs, people often use the term merge instead of join.
A Note on Op-Based CRDTS
As mentioned above, many CRDT fans like to talk about two “different” kinds of CRDTs: normal (“state-based”) semilattice CRDTs, and something called “op-based” CRDTs. I’m here to tell you that correct op-based CRDTs are also semilattices; the distinction is not fundamental.
An “op-based” CRDT is just a particular class of semilattice. The state of an op-based CRDT represents a partially-ordered log of operations (opaque commands). The CRDT’s job is to ensure that the partially-ordered log is consistent across nodes.
1.14.5. Used in Interoperable Distributed Components
1.14.6. Replicated Data Types as composable types
Say you have an underlying document A
If you make a operation on it, you generate code that can change that state and ideally also revert it to the previous state (transactional update), but it must made a set of assumptions about the underlying document
For example: adding an element to the second list in the document is composable with adding another element to the second list of the document is composable
Deleting the second list in the document is not composable with adding an element to the second list in the document
If these generated functions cannot compose, there has been a conflicting concurrent update
Is like saving state in the data type itself
1.14.7. Tree CRDT
1.14.9. CRDTs Turned Inside Out
1.14.13. You might not need a CRDT | Hacker News
Comments → there is no tree algorightm for trees
You need a traversal order to turn a tree into a flat list, and then you can define an CRDT
1.14.13.2. Where is the CRDT for syntax trees
1.14.16. Lies I was told about collab editing, Part 1: Algorithms for offline editing | Hacker News
1.14.16.1. Lies I was Told About Collaborative Editing, Part 1: Algorithms for offline editing / Moment devlog
:ID: eeadd9f7-a431-42b8-91d0-0a6032aa7ac2