sql
Table of Contents
- 1. sql
- 1.1. Links
- 1.2. Introductory
- 1.3. Sublenguajes SQL
- 1.4. Formas normales
- 1.5. Wide vs Narrow tables
- 1.6. Entity-Relationship model
- 1.7. Ejecutar varias consultas dependientes en SQLAlchemy
- 1.8. Imprimir una query en SQLAlchemy
- 1.9. Upsert
- 1.10. Join explicado
- 1.11. MySQL
- 1.12. PostgreSQL
- 1.13. BigQuery
- 1.14. Tools
- 1.15. Everything in SQL
- 1.15.1. mechatroner/RBQL: 🦜RBQL - Rainbow Query Language: SQL-like query engine for (not only) CSV file processing. Supports SQL queries with Python and JavaScript expressions.
- 1.15.2. shilelagh: everything in SQL
- 1.15.3. Presto
- 1.15.4. Yet another find + grep : rust
- 1.15.5. SQL in Jupyter
- 1.15.6. osquery/osquery: SQL powered operating system instrumentation, monitoring, and analytics.
- 1.15.7. Steampipe | select * from cloud;
- 1.16. Patrones SQL
- 1.17. Trucos
- 1.18. Referencia
- 1.19. SQL Iceberg
1. sql
1.1. Links
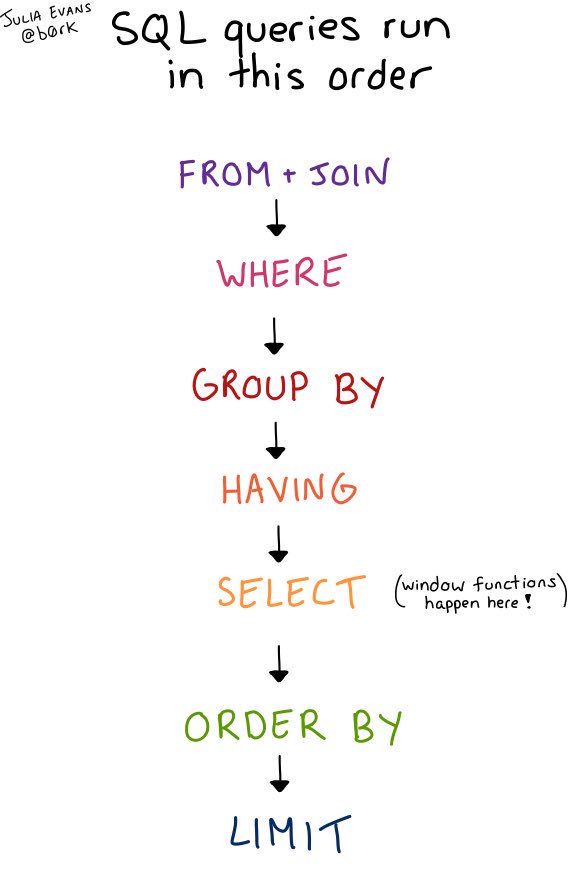

1.2. Introductory
- https://www.perplexity.ai/sql
Perplexity SQL answers Twitter graph queries by translating natural language to SQL code.
1.3. Sublenguajes SQL
https://www.geeksforgeeks.org/sql-ddl-dql-dml-dcl-tcl-commands/
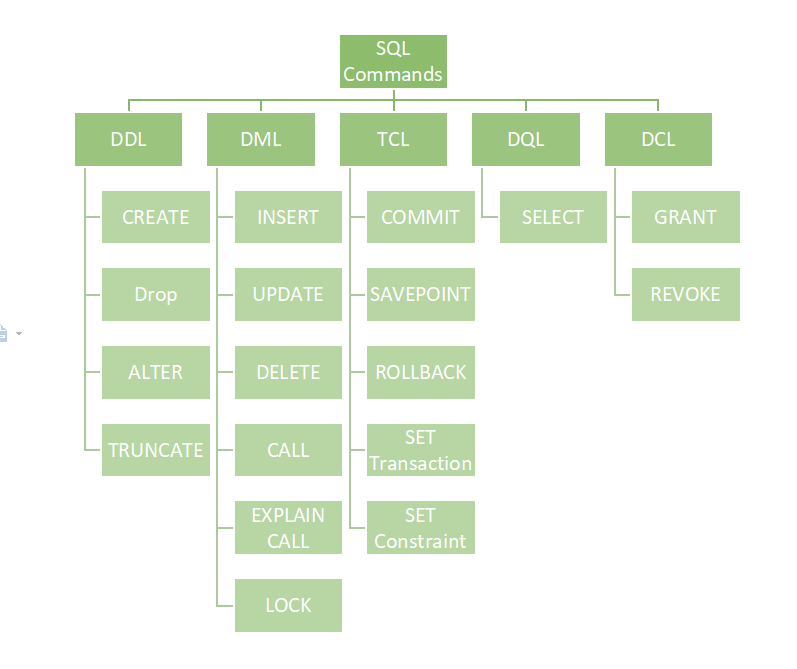
- Data Definition Language (DDL)
- CREATE: create the database or its objects (like table, index, function, views, store procedure, and triggers).
- DROP: delete objects from the database.
- ALTER: alter the structure of the database.
- TRUNCATE: remove all records from a table, including all spaces allocated for the records are removed.
- COMMENT: add comments to the data dictionary.
- RENAME: rename an object existing in the database.
- CREATE: create the database or its objects (like table, index, function, views, store procedure, and triggers).
- Data Query Language (DQL)
- SELECT: retrieve data from the database.
- SELECT: retrieve data from the database.
- Data Manipulation Language (DML)
- INSERT : insert data into a table.
- UPDATE: update existing data within a table.
- DELETE : delete records from a database table.
- LOCK: Table control concurrency.
- CALL: Call a PL/SQL or JAVA subprogram.
- EXPLAIN PLAN: describes the access path to data.
- INSERT : insert data into a table.
- Data Control Language (DCL)
- GRANT: gives users access privileges to the database.
- REVOKE: withdraws the user’s access privileges given by using the GRANT command.
- GRANT: gives users access privileges to the database.
- Transaction Control Language (TCL)
- COMMIT: Commits a Transaction.
- ROLLBACK: Rollbacks a transaction in case of any error occurs.
- SAVEPOINT:Sets a savepoint within a transaction.
- SET TRANSACTION: Specify characteristics for the transaction.
- COMMIT: Commits a Transaction.

1.4. Formas normales
- Las 6+2 formas normales de las bases de datos relacionales
- https://forum.thethirdmanifesto.com/wp-content/uploads/asgarosforum/987737/00-efc-further-normalization.pdf
- https://towardsdatascience.com/database-normalization-explained-53e60a494495
- First Normal Form (1NF):
- Data is stored in tables with rows uniquely identified by a primary key (autoincremental id)
- Data within each table is stored in individual columns in its most reduced form (columns named
field1_and_field2are a good indicator) - There are no repeating groups (
field_1,field_2, …, a field that is a list, or a list in string form, delimiter-separated). Usually they go into a separated table which allows one-to-many/many-to-many relations
- Data is stored in tables with rows uniquely identified by a primary key (autoincremental id)
- Second Normal Form (2NF):
- Everything from 1NF
- Only data that relates to a table’s primary key is stored in each table(e.g. if you have a
entity_name,entity_created_at, … then you need a separate entity)
- Everything from 1NF
- Third Normal Form (3NF):
- Everything from 2NF
- There are no in-table dependencies between the columns in each table
- Everything from 2NF
- First Normal Form (1NF):
1.4.2. Normalizing vs. Denormalizing Databases
1.4.2.1. Some Good Reasons Not to Normalize
- Joins are expensive. Normalizing your database often involves creating lots of tables. If you can stick all of the data used by that query into a single table without really jeopardizing your data integrity, go for it!
- Normalized design is difficult.
- Quick and dirty should be quick and dirty.
- If you’re using a NoSQL database, traditional normalization is not desirable. Instead, design your database using the BASE model which is far more forgiving. This is useful when you are storing unstructured data such as emails, images or videos.
1.5. Wide vs Narrow tables
- https://en.wikipedia.org/wiki/Wide_and_narrow_data
- I Wish My Relational Database Tables Were Narrower
- Narrow tables mean less data needs to be read off of disk.
- Narrow tables mean less data needs to be kept in the database’s “working memory”.
- Migrating data is generally easier with narrow tables since it is typically faster and safer to create new tables when compared to adding new columns to an existing table.
- Narrow tables force you to think more critically about your data-model; and about elevating related columns into a more official entity concept.
- Narrow tables may lead to fewer transactional locks.
- Narrow tables may make it easier to create covering indexes for better performance.
- Narrow tables may make it easier to design unique indexes that prevent dirty-data through idempotency without then need for transactional locks.
- Narrow tables may lead to shorter tables (ie, tables with fewer rows) which means your indexes require less processing overhead to maintain.
- Narrow tables make it easier to avoid using
NULLvalues - andNULLvalues should be avoided as much as possible (though not always). - Narrow tables also mean that some of your queries become more complex with JOIN clauses;
- or that your application code becomes more complex with “application joins”.
- But, if narrow tables also map more closely to your data access patterns, then this isn’t as big a downside as you might, at first, consider it.
- Narrow tables mean less data needs to be read off of disk.
1.7. Ejecutar varias consultas dependientes en SQLAlchemy
con = engine.connect() sql = text("SET @quot=-1") con.execute(sql) df = pd.read_sql(query, con)
1.8. Imprimir una query en SQLAlchemy
- python - How do I get a raw, compiled SQL query from a SQLAlchemy expression? - Stack Overflow
- Engine Configuration — SQLAlchemy 2.0 Documentation
from sqlalchemy import create_mock_engine from sqlalchemy.sql import text def dump(sql, *multiparams, **params): print(sql.compile(dialect=engine.dialect)) engine_mock = create_mock_engine('postgresql://', dump, echo=True) engine_mock.execute(str_sql, start_date=start_date) engine = sqlalchemy.create_engine('postgres://foo/bar', echo=True) # Con esto también funciona, aunque creo que no te rellena todos los parámetros
Hay que pasarle alguna información extra a execute y/o compile para que rellene los parámetros, pero no encuentro manera de hacerlo
1.9. Upsert
with subquery as ( select * from my_table where :condition) insert into new_table(field1, field2, ...) select field1, field2, ... from subquery on conflict(primary_key_condition) do update set field1 = EXCLUDED.field1
1.10. Join explicado
DISCLAIMER: Probablemente el dibujo lo hace más lioso pero al menos yo me entiendo
Lo que en programación imperativa es un for, en SQL se transforma en un join
1.10.1. Join como producto cartesiano
Por defecto, un join sin ninguna condición, te genera un producto cartesiano de las dos tablas, es decir, todas las combinaciones posibles entre las dos tablas:
select a.*, b.* from LeftTable a join RightTable b
for a in LeftTable: for b in RightTable result = concat([a, b])
Las condiciones que pongas te seleccionan una “línea” en el diagrama de abajo según se cumpla una condición u otra

1.11. MySQL
1.11.1. Info de espacio libre
-- Get the database free space SELECT table_schema "Data Base Name", sum( data_length + index_length ) / 1024 / 1024 "Data Base Size in MB", sum( data_free )/ 1024 / 1024 "Free Space in MB" FROM information_schema.TABLES GROUP BY table_schema; -- Get the database last update ordered by update time then by create time. SELECT MAX(UPDATE_TIME), MAX(CREATE_TIME), TABLE_SCHEMA FROM `TABLES` GROUP BY TABLE_SCHEMA ORDER BY 1, 2;
1.11.2. Simular lag en MySQL
1.11.3. Matar procesos que se quedan abiertos desde MySQL
SHOW PROCESSLIST; KILL 38239; KILL 38240; -- Para hacerlo más automático, se puede hacer lo sigiente: -- También matchea el propio proceso que ejecuta la query, -- por lo que siempre devuelve un resultado al menos select concat('KILL ',id,';') from information_schema.processlist -- where INFO like "%FaultyTable%" -- Filtro opcional
https://stackoverflow.com/questions/24496918/mysql-slow-drop-table-command
https://stackoverflow.com/questions/3638689/how-to-see-full-query-from-show-processlist
select * from INFORMATION_SCHEMA.PROCESSLIST where db = 'somedb';
1.11.4. Backup de una tabla
CREATE TABLE db.backup LIKE db.mytable; INSERT db.backup SELECT * FROM db.mytable;
1.11.5. MySQL Time Type
1.11.7. MySQL Calendar
https://stackoverflow.com/questions/10132024/how-to-populate-a-table-with-a-range-of-dates
DROP PROCEDURE IF EXISTS filldates; DELIMITER | CREATE PROCEDURE filldates(dateStart DATE, dateEnd DATE) BEGIN WHILE dateStart <= dateEnd DO INSERT INTO calendar (calendar_date) VALUES (dateStart); SET dateStart = date_add(dateStart, INTERVAL 1 DAY); END WHILE; END; | DELIMITER ; DROP TABLE IF EXISTS calendar CREATE TABLE IF NOT EXISTS calendar(calendar_date DATE NOT NULL PRIMARY KEY); CALL filldates('2021-01-01','2021-09-06'); select * from calendar
DROP PROCEDURE IF EXISTS filldates; DELIMITER | CREATE PROCEDURE filldates(dateStart TIMESTAMP, dateEnd TIMESTAMP) BEGIN WHILE dateStart <= dateEnd DO INSERT INTO calendar (calendar_date) VALUES (dateStart); SET dateStart = adddate(dateStart, INTERVAL 15 MINUTE); END WHILE; END; | DELIMITER ; DROP TABLE IF EXISTS calendar CREATE TABLE IF NOT EXISTS calendar(calendar_date TIMESTAMP ); CALL filldates('2021-01-01','2021-01-02');
1.11.8. Import/Export MySQL
docker run -it --name some-mysql -v /media/julian/volume/mysql:/var/lib/mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=my-secret-pw mysql
mysql -u root -p mysql -h 127.0.0.1 < out.sql
1.12. PostgreSQL
1.13. BigQuery
1.14. Tools
1.14.1. dbeaver
1.15. Everything in SQL
1.15.2. shilelagh: everything in SQL
1.15.3. Presto
allows users to query data sources such as Hadoop, Cassandra, Kafka, AWS S3, Alluxio, MySQL, MongoDB and Teradata,[1] and allows use of multiple data sources within a query.
1.15.4. Yet another find + grep : rust
SQL queries to files
1.15.5. SQL in Jupyter
1.15.7. Steampipe | select * from cloud;
1.16. Patrones SQL
1.16.1. Seleccionar último registro
select * from mytable join ( select max(created_at) from mytable group by id ) latest on mytable.id = latest.id
1.16.2. Upsert
Al subir un csv, el orden de campos importa, por lo que es mejor:
- Subir la tabla a una tabla temporal asegurándonos de que tiene el
mismo esquema (o creándolo automáticamente en python, por ejemplo) - Hacer un upsert (update+insert) de los campos que hemos incluido
1.16.3. lag, nulos
Cuando haces un lag, te salen nulos
timestamp > lag(timestamp) -- OJO! Esto excluye registros con timestamp nulo! timestamp > coalesce(lag(timestamp), min_timestamp)
1.16.4. Copia de una tabla
-- Hacer un backup de la tabla de table_name_1 create table table_name_backup as (select * from table_name_1 mg) -- Comprobar que el backup se ha creado select * from table_name_backup -- Tirar la tabla de table_name_1 drop table table_name_1 -- Copiar de vuelta los valores en la nueva tabla insert into table_name_1 (grid_id, region_id, inside, min_lon, max_lon, min_lat, max_lat) select grid_id, region_id, inside, min_lon, max_lon, min_lat, max_lat from table_name_backup -- Comprobar que la tabla se ha copiado bien desde el backup select * from table_name_1 -- Tirar la tabla de table_name_backup drop table table_name_backup
1.16.5. Insertar múltiples registros
https://stackoverflow.com/questions/758945/whats-the-fastest-way-to-do-a-bulk-insert-into-postgres
Postgres
INSERT INTO films (code, title, did, date_prod, kind) VALUES ('B6717', 'Tampopo', 110, '1985-02-10', 'Comedy'), ('HG120', 'The Dinner Game', 140, DEFAULT, 'Comedy');
1.16.6. De With a Tabla
Según vas necesitando más niveles de persistencia
- With
- Temporary Table
- (Materialized) View
- Table
1.17. Trucos
- Al atascarse en una query, puede ser útil cambiar el orden en el que se ejecutan las queries: sacar una subquery al nivel superior, hacer primero un cruce que se hace más adelante…
1.17.1. Cuentas distintas sobre una misma tabla
select c.name->>"$.translations.en" as "Ciudad", coalesce(created_at, 0) as "Día", coalesce(sum(created_at >= '2020-04-01 02:00:00' and created_at < '2020-05-01 02:00:00'), 0) as "Registrados", coalesce(sum(accept_date >= '2020-04-01 02:00:00' and accept_date < '2020-05-01 02:00:00'), 0) as "Validados" from motit.iterable i left join motit.`User` u on i.num = date(u.created_at) left join motit.City c on u.city_id = c.id where created_at >= '2020-04-01 02:00:00' and created_at < '2020-05-01 02:00:00' group by 1, 2 order by c.name->>"$.translations.en", date(created_at) Básicamente haces un select sum(condición 1 que iria en el where) as cuenta1, sum(condición 2 que iria en el where) as cuenta2
1.17.2. Cuentas de usuarios que no han comprado (join vs where)
select count(distinct user_id) as users_without_payments from user_list ul left join Payments p on ul.user_id = p.user_id and p.payment_at >= '2020-10-01 04:00:00' and p.payment_at < '2021-10-04 22:00:00' where p.id is null
El truco es que el cruce y la condición temporal van en el JOIN, pero la condición de que sea nulo va en el WHERE, que es más restrictivo.
Si pones todo en el JOIN, te cuenta todos los usuarios, y si pones todo en el where, no te encuentra nada porque sólo está sacando los usuarios que matchean
1.17.3. Alter table con Add no lleva column
https://www.w3schools.com/sql/sql_alter.asp
El resto sí que lo llevan
1.17.4. full outer join con left+right join
SELECT * FROM t1 LEFT JOIN t2 ON t1.id = t2.id UNION SELECT * FROM t1 RIGHT JOIN t2 ON t1.id = t2.id
1.17.5. Pruebas aleatorias
-- Esto para sacar los registros que hay de cada tipo -- Luego calibramos las probabilidades aprox con esto select cond1, cond2, count(*) from table1 group by cond1, cond2 select * from table1 join ... where table1.id = ( -- Las probabilidades las aproximamos aquí en función del número de registros que queremos select id where cond1=1 and cond2=1 and rand() < 0.01 union select id where cond1=0 and cond2=1 and rand() < 0.1 union select id where cond1=1 and cond2=1 and rand() < 0.9 -- Ponemos rand() < <fraccion> porque asi es más fácil de calcular
1.18. Referencia
1.18.1. lag
LAG(expression [,offset [,default_value]])
OVER (
[PARTITION BY partition_expression, ... ]
ORDER BY sort_expression [ASC | DESC], ...
)